
단순한 Softmax 함수는 numerical instability하다.
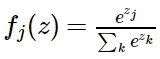
e의 지수연산을 하게 되므로, 쉽게 오버플로 혹은 언더플로가 발생할 수 있다.
예를 들어 [100, 200, 300] (너무 큰 값들의 list)을 soft max function에 단순 계산하게 된다면, overflow가 발생하여,
가장 큰 값에만 1에 근사한 값이 들어가고 나머지 class에는 0에 가까운 값이 들어간다. ([0.000..., 0.000..., 1])
반대로, [1/1000, 1/2000, 1/3000](너무 작은 값들의 list)을 전사한다면,
under flow가 발생하여, soft max함수 결과는 각각의 성분에 동일하게(uniform하게) 들어가게 된다. ( [0.33333.., 0.33333..., 0.33333...] )
→ 이 해결방안: parametric trick=상수를 분모 분자에 곱해주어 이를 shift해주고 안정적이게 mapping해주는 방법이다.

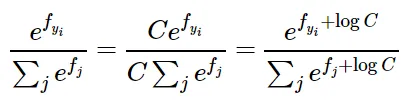
'머신러닝 이모저모' 카테고리의 다른 글
| Parse Tree : Dependency 와 Constituency (0) | 2025.02.13 |
|---|---|
| VScode Debug configuration file 만들기 : accelerate 와 deepspeed (1) | 2024.11.09 |
| cuda downgrade 하기 (4) | 2024.11.08 |
| DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models (0) | 2024.11.07 |
| Peft save_pretrained() 에러 : UnboundLocalError: local variable 'active_adapters' referenced before assignment (0) | 2024.10.20 |
단순한 Softmax 함수는 numerical instability하다.
e의 지수연산을 하게 되므로, 쉽게 오버플로 혹은 언더플로가 발생할 수 있다.
예를 들어 [100, 200, 300] (너무 큰 값들의 list)을 soft max function에 단순 계산하게 된다면, overflow가 발생하여,
가장 큰 값에만 1에 근사한 값이 들어가고 나머지 class에는 0에 가까운 값이 들어간다. ([0.000..., 0.000..., 1])
반대로, [1/1000, 1/2000, 1/3000](너무 작은 값들의 list)을 전사한다면,
under flow가 발생하여, soft max함수 결과는 각각의 성분에 동일하게(uniform하게) 들어가게 된다. ( [0.33333.., 0.33333..., 0.33333...] )
→ 이 해결방안: parametric trick=상수를 분모 분자에 곱해주어 이를 shift해주고 안정적이게 mapping해주는 방법이다.
'머신러닝 이모저모' 카테고리의 다른 글
| Parse Tree : Dependency 와 Constituency (0) | 2025.02.13 |
|---|---|
| VScode Debug configuration file 만들기 : accelerate 와 deepspeed (1) | 2024.11.09 |
| cuda downgrade 하기 (4) | 2024.11.08 |
| DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models (0) | 2024.11.07 |
| Peft save_pretrained() 에러 : UnboundLocalError: local variable 'active_adapters' referenced before assignment (0) | 2024.10.20 |