
요즘 LLM 이 유행하면서 빠질 수 없는 기술인 Parallelism 에 대해 정리해보도록 하자!
여러 GPU deivce 를 사용하는 Parallelism (병렬화)은 데이터 parallel 과 모델 parallel 로 나뉘어진다.
Parallelism 은 여러 GPU 를 사용해서 하나의 학습과정을 더 빨리 끝내거나 모델이 너무 커서 하나의 GPU에 다 올라가지 않을 때 분할학습을 할 수 있도록 하는 기술이다.
전자는 Data Parallel 류의 방법을 사용하고 후자의 경우에는 Model Parallel 류의 방법을 사용한다.
(실제로 크게 DP MP 로 나뉘고 그 아래 DDP 나 PP, TP 등 advanced 방법이 포함되어있지는 않지만 그냥 이해를 편하게 하기 위해 이렇게 기재하였다)
Data Parallel (DP)
DP 는 같은 모델이 여러 gpu 메모리에 복사되어 load 되고 각 GPU 마다 다른 micro batch 가 input 으로 들어가 처리된다.
이렇게 데이터를 나눠서 처리할 때 여러 개 GPU 를 사용하지만 main GPU 가 있다. (이를 master process 라고 하고 보통 0번이다.)
이를 이용해 각각 GPU 에서 forward 한 logit output 을 이용하여 loss 를 계산한다.
이후 back prop 에서는 계산된 loss 를 이용하여 각 gpu에 다시 전달받고 gradient 를 구해서 다시 master gpu 에 전달하여 모델을 업데이트하고 업데이트된 모델은 다시 다른 gpu에 복사해야한다.
위의 활동이 비효율적인 이유는 GPU 간의 통신 시간이 매우 오래 걸리는 이기 때문이다!
또한 main gpu 가 다른 gpu 에 비해 더 많은 메모리를 사용한다.
DP 의 단점은 매 스텝마다 다른 gpu로 업데이트된 모델이 복제(broadcast) 되어야 한다는 것이다.
** 이를 해결하기 위해 All-Reduce 라는 방법이 있다고 한다.
DP 의 또다른 단점으로는 딥러닝에서 많이 사용되는 프로그래밍 언어인 파이썬과의 호환 이다.
파이썬은 multi-process 는 지원하지만 multi-thread 는 지원하지 않는다.
하지만 DP 는 single-process multi-thread 모듈이기 때문에 파이썬에서 효율적이지 않다.
** DP 는 또한 single machine 에서만 동작한다!
Distributed Data Parallel (DDP)
DDP 는 위에서 말한 All-Reduce 방법을 개선한 Ring-All-Reduce 방법을 활용한다.
위의 DP 기술은 GPU간에 정보를 전달하기 위해 시간이 걸린다는 단점이 있다.
이를 보완하기 위한 기술이 DDP 인데, 각 GPU 의 모델을 동시에 업데이트 하지 않아도 되기 때문에 모델을 매번 복제하지 않아도 된다.
또한 마스터 프로세스가 없기 때문에 특정 디바이스에만 load 가 부과되지 않는다.
Multi-process 모듈이고, 하나의 GPU 에 하나의 process 만 동작한다.
** Single machine 과 Multi machine 에서 모두 동작할 수 있다.
Model Parallel (MP)
모델을 여러 GPU 에 나누는 방식도 있다.
MP 는 layer 단위로 각 1개 나 여러개 layer 단위로 나뉘어서 여러 개 gpu 에 들어가 계산된다. 이를 Vertical MP 라고도 한다.
이 방법의 문제점은 밑의 그림과 같이 0번 디바이스가 계산되면 레이어마다 순서대로 계산되어야하기 때문에 다른 디바이스는 hold 되어야 한다. 이렇게 낭비되는 시간을 idle time 이라고 한다.
그래서 예를 들면 6G GPU 4개를 MP 하여 사용하는 것은 24G GPU 1개를 사용하는 것과 똑같은데, 후자는 (심지어) data 복사 overhead 가 없기 때문에 더 빨리 학습할 수 있다.
Pipeline Parallel (PP)

위 그림은 Naive(바닐라) Model Parallel 과 PP 를 비교한 그림이다.
F 는 Forward propagation 이라고 하고 B 는 Backward propagation 이라는 뜻이다.
device 가 4개이기 때문에 model 을 레이어 단위로 4개로 나눴다고 할 수 있다.
PP에서는 위의 naive MP 문제를 완화하기 위해 batch 를 micro-batch 로 나누어서(=chuncking) 각 디바이스에 넣는다.
예를 들어 (global) batch size=64 이고 4개 chunk 로 나누기로 할 때 (chunk 의 개수와 GPU 의 개수 는 서로 같아야 하나?), micro-batch size 는 64/4=16 이 된다!
위의 그림에서 PP 의 chunk 개수는 4개이고, naive MP 의 chunk 개수는 1개 라고 할 수 있다.
batch 에 대해 pipeline 에서 각 다른 stage 에서 프로세스된다.
그럼에도 불구하고 PP 도 idle time 이 생기는데 위 그림에서 Bubble 이라고 한다.
Interleaved Pipeline

위 PP 의 Bubble 을 줄이기 위해 위와 같은 방법을 사용하기도 한다.
Tensor Parallel (TP)
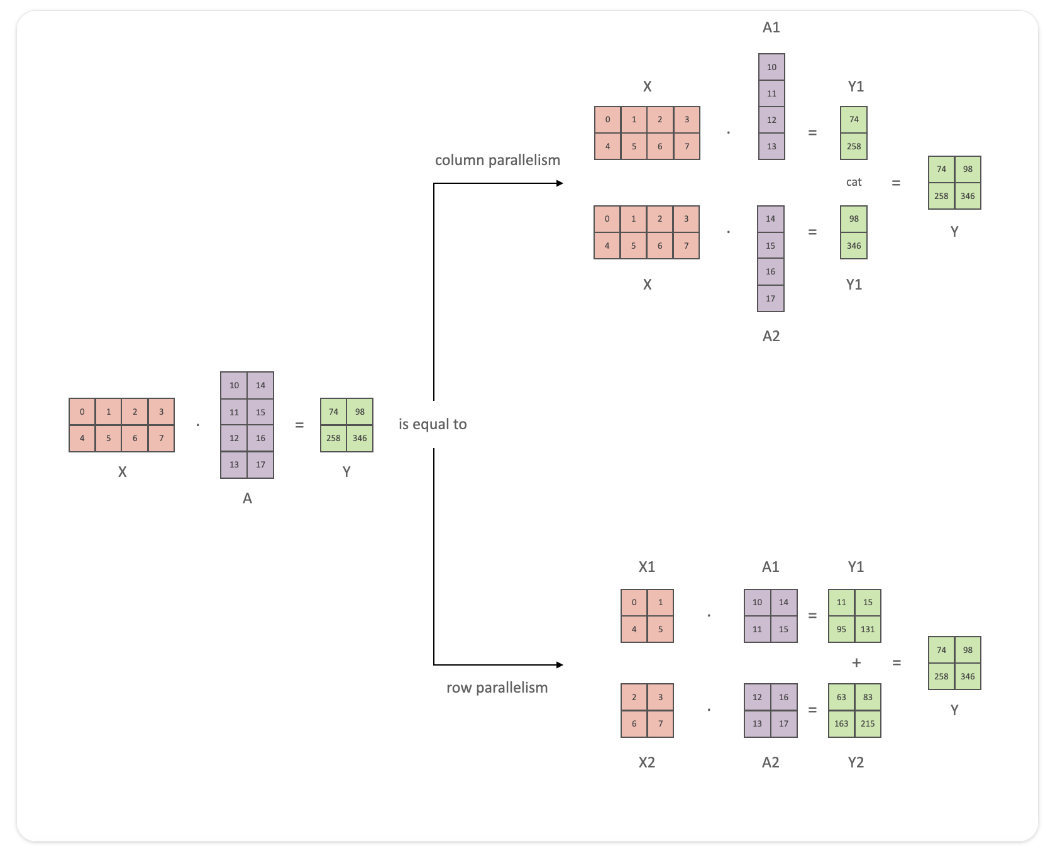
TP는 각 텐서를 여러 chunk 로 나눠 gpu에 각각 계산된다.
Step 이 완료되면 synchronize 한다.
Horizontal parallelism 이라고도 한다.
그 이외에도 Zero Redundancy Optimizer (ZeRO) 등이 있다.
(ZeRO 는 TP 와 비슷한 방법이다)
2D 3D Parallelism
위에서 설명한 병렬화 기술들은 다 한 가지 요소(데이터, 모델)에 대한 1D parallel 기술이라고 할 수 있다.
이 기술들을 여러 개 같이 사용하면 이를 2D 3D parallelism 이라고 한다.
2D 에는 DP+PP 를 함께 사용하는 방법이 있다.

2D parallelism 을 사용하기 위해서는 적어도 GPU 4개가 필요하다.
위의 그림을 보면 GPU0 과 2에서 1개의 DP 를 하고 다른 1 3 에서 다른 Data 에 대해 DP 를 한다.
마지막의 보라색 AR 은 All-Reduce 를 의미한다.
3D 에는 DP+PP+TP 를 함께 사용하는 방법이 있다.

3D parallelism 에서는 적어도 GPU 8개가 필요하다.
참조
https://huggingface.co/docs/transformers/v4.15.0/parallelism
Model Parallelism
huggingface.co
https://tutorials.pytorch.kr/intermediate/ddp_tutorial.html
분산 데이터 병렬 처리 시작하기
저자: Shen Li 감수: Joe Zhu 번역: 조병근 선수과목(Prerequisites): PyTorch 분산 처리 개요, 분산 데이터 병렬 처리 API 문서, 분산 데이터 병렬 처리 문서. 분산 데이터 병렬 처리(DDP)는 여러 기기에서 실행
tutorials.pytorch.kr
https://algopoolja.tistory.com/m/95
torch의 데이터 분산 연산(DP 와 DDP)
torch parallelism Pytorch 를 사용해 모델을 학습하다 보면 여러가지 병렬화를 사용합니다. 병렬화를 사용하는 이유는 크게 2가지로 나눠볼 수 있습니다. 학습을 더 빨리 끝내기 위해 모델이 너무 커서
algopoolja.tistory.com
'Python 및 Torch 코딩 이모저모' 카테고리의 다른 글
| HuggingFace Trainer 학습이 중간에 끊겼을 때 (0) | 2024.02.25 |
|---|---|
| HuggingFace OSError: You are trying to access a gated repo.Make sure to request access at 에러 (0) | 2024.01.24 |
| 리눅스에 파이썬 새로운 버전 설치하기! (0) | 2023.10.25 |
| HuggingFace 실습(PEFT) : 2. Train (0) | 2023.10.17 |
| HuggingFace 실습(PEFT) : 1. Data (0) | 2023.10.15 |
요즘 LLM 이 유행하면서 빠질 수 없는 기술인 Parallelism 에 대해 정리해보도록 하자!
여러 GPU deivce 를 사용하는 Parallelism (병렬화)은 데이터 parallel 과 모델 parallel 로 나뉘어진다.
Parallelism 은 여러 GPU 를 사용해서 하나의 학습과정을 더 빨리 끝내거나 모델이 너무 커서 하나의 GPU에 다 올라가지 않을 때 분할학습을 할 수 있도록 하는 기술이다.
전자는 Data Parallel 류의 방법을 사용하고 후자의 경우에는 Model Parallel 류의 방법을 사용한다.
(실제로 크게 DP MP 로 나뉘고 그 아래 DDP 나 PP, TP 등 advanced 방법이 포함되어있지는 않지만 그냥 이해를 편하게 하기 위해 이렇게 기재하였다)
Data Parallel (DP)
DP 는 같은 모델이 여러 gpu 메모리에 복사되어 load 되고 각 GPU 마다 다른 micro batch 가 input 으로 들어가 처리된다.
이렇게 데이터를 나눠서 처리할 때 여러 개 GPU 를 사용하지만 main GPU 가 있다. (이를 master process 라고 하고 보통 0번이다.)
이를 이용해 각각 GPU 에서 forward 한 logit output 을 이용하여 loss 를 계산한다.
이후 back prop 에서는 계산된 loss 를 이용하여 각 gpu에 다시 전달받고 gradient 를 구해서 다시 master gpu 에 전달하여 모델을 업데이트하고 업데이트된 모델은 다시 다른 gpu에 복사해야한다.
위의 활동이 비효율적인 이유는 GPU 간의 통신 시간이 매우 오래 걸리는 이기 때문이다!
또한 main gpu 가 다른 gpu 에 비해 더 많은 메모리를 사용한다.
DP 의 단점은 매 스텝마다 다른 gpu로 업데이트된 모델이 복제(broadcast) 되어야 한다는 것이다.
** 이를 해결하기 위해 All-Reduce 라는 방법이 있다고 한다.
DP 의 또다른 단점으로는 딥러닝에서 많이 사용되는 프로그래밍 언어인 파이썬과의 호환 이다.
파이썬은 multi-process 는 지원하지만 multi-thread 는 지원하지 않는다.
하지만 DP 는 single-process multi-thread 모듈이기 때문에 파이썬에서 효율적이지 않다.
** DP 는 또한 single machine 에서만 동작한다!
Distributed Data Parallel (DDP)
DDP 는 위에서 말한 All-Reduce 방법을 개선한 Ring-All-Reduce 방법을 활용한다.
위의 DP 기술은 GPU간에 정보를 전달하기 위해 시간이 걸린다는 단점이 있다.
이를 보완하기 위한 기술이 DDP 인데, 각 GPU 의 모델을 동시에 업데이트 하지 않아도 되기 때문에 모델을 매번 복제하지 않아도 된다.
또한 마스터 프로세스가 없기 때문에 특정 디바이스에만 load 가 부과되지 않는다.
Multi-process 모듈이고, 하나의 GPU 에 하나의 process 만 동작한다.
** Single machine 과 Multi machine 에서 모두 동작할 수 있다.
Model Parallel (MP)
모델을 여러 GPU 에 나누는 방식도 있다.
MP 는 layer 단위로 각 1개 나 여러개 layer 단위로 나뉘어서 여러 개 gpu 에 들어가 계산된다. 이를 Vertical MP 라고도 한다.
이 방법의 문제점은 밑의 그림과 같이 0번 디바이스가 계산되면 레이어마다 순서대로 계산되어야하기 때문에 다른 디바이스는 hold 되어야 한다. 이렇게 낭비되는 시간을 idle time 이라고 한다.
그래서 예를 들면 6G GPU 4개를 MP 하여 사용하는 것은 24G GPU 1개를 사용하는 것과 똑같은데, 후자는 (심지어) data 복사 overhead 가 없기 때문에 더 빨리 학습할 수 있다.
Pipeline Parallel (PP)
위 그림은 Naive(바닐라) Model Parallel 과 PP 를 비교한 그림이다.
F 는 Forward propagation 이라고 하고 B 는 Backward propagation 이라는 뜻이다.
device 가 4개이기 때문에 model 을 레이어 단위로 4개로 나눴다고 할 수 있다.
PP에서는 위의 naive MP 문제를 완화하기 위해 batch 를 micro-batch 로 나누어서(=chuncking) 각 디바이스에 넣는다.
예를 들어 (global) batch size=64 이고 4개 chunk 로 나누기로 할 때 (chunk 의 개수와 GPU 의 개수 는 서로 같아야 하나?), micro-batch size 는 64/4=16 이 된다!
위의 그림에서 PP 의 chunk 개수는 4개이고, naive MP 의 chunk 개수는 1개 라고 할 수 있다.
batch 에 대해 pipeline 에서 각 다른 stage 에서 프로세스된다.
그럼에도 불구하고 PP 도 idle time 이 생기는데 위 그림에서 Bubble 이라고 한다.
Interleaved Pipeline
위 PP 의 Bubble 을 줄이기 위해 위와 같은 방법을 사용하기도 한다.
Tensor Parallel (TP)
TP는 각 텐서를 여러 chunk 로 나눠 gpu에 각각 계산된다.
Step 이 완료되면 synchronize 한다.
Horizontal parallelism 이라고도 한다.
그 이외에도 Zero Redundancy Optimizer (ZeRO) 등이 있다.
(ZeRO 는 TP 와 비슷한 방법이다)
2D 3D Parallelism
위에서 설명한 병렬화 기술들은 다 한 가지 요소(데이터, 모델)에 대한 1D parallel 기술이라고 할 수 있다.
이 기술들을 여러 개 같이 사용하면 이를 2D 3D parallelism 이라고 한다.
2D 에는 DP+PP 를 함께 사용하는 방법이 있다.
2D parallelism 을 사용하기 위해서는 적어도 GPU 4개가 필요하다.
위의 그림을 보면 GPU0 과 2에서 1개의 DP 를 하고 다른 1 3 에서 다른 Data 에 대해 DP 를 한다.
마지막의 보라색 AR 은 All-Reduce 를 의미한다.
3D 에는 DP+PP+TP 를 함께 사용하는 방법이 있다.
3D parallelism 에서는 적어도 GPU 8개가 필요하다.
참조
https://huggingface.co/docs/transformers/v4.15.0/parallelism
Model Parallelism
huggingface.co
https://tutorials.pytorch.kr/intermediate/ddp_tutorial.html
분산 데이터 병렬 처리 시작하기
저자: Shen Li 감수: Joe Zhu 번역: 조병근 선수과목(Prerequisites): PyTorch 분산 처리 개요, 분산 데이터 병렬 처리 API 문서, 분산 데이터 병렬 처리 문서. 분산 데이터 병렬 처리(DDP)는 여러 기기에서 실행
tutorials.pytorch.kr
https://algopoolja.tistory.com/m/95
torch의 데이터 분산 연산(DP 와 DDP)
torch parallelism Pytorch 를 사용해 모델을 학습하다 보면 여러가지 병렬화를 사용합니다. 병렬화를 사용하는 이유는 크게 2가지로 나눠볼 수 있습니다. 학습을 더 빨리 끝내기 위해 모델이 너무 커서
algopoolja.tistory.com
'Python 및 Torch 코딩 이모저모' 카테고리의 다른 글
| HuggingFace Trainer 학습이 중간에 끊겼을 때 (0) | 2024.02.25 |
|---|---|
| HuggingFace OSError: You are trying to access a gated repo.Make sure to request access at 에러 (0) | 2024.01.24 |
| 리눅스에 파이썬 새로운 버전 설치하기! (0) | 2023.10.25 |
| HuggingFace 실습(PEFT) : 2. Train (0) | 2023.10.17 |
| HuggingFace 실습(PEFT) : 1. Data (0) | 2023.10.15 |