
(IA)3 paper 등에서 제시한 Prompt Tuning 의 문제점
: Prompt network 의 initialization 이 성능에 매우 큰 영향을 미친다.
이 문제점이 가장 처음 제기된 논문이다.
기존 Prompt Tuning 의 문제점
- 모델 capacity 가 증가할수록 프롬프트 튜닝이 파인튜닝에 성능이 근접해간다. 하지만 11B 이하 작은 모델로는 이 두 방법론의 성능 사이에 큰 차이가 존재한다.
이를 해결하기 위해 Source task 로 학습된 프롬프트를 Transfer 에 이용하여 Target task 의 성능을 높일 것을 제안한다.
Method

(right Fig.)
1개 이상의 source task 에 대해 (frozen model에서) prompt 를 학습하고
이 프롬프트를 초기화값으로 사용하여 target task 를 학습한다.
Spot 은 프롬프트 튜닝의 computational benefit을 유지한다.: 각 타겟 태스크에 대해 작은 task-specific prompt 만 저장하면 되고 1개의 frozen LM 에서 모든 태스크에 대해 다시 사용할 수 있다.
Base model
Pre-trained T5 모델 SMALL (60M), BASE (220M), LARGE (770M), XL (3B), XXL (11B) 사용.
baseline
- 바닐라 프롬프트 튜닝 : 각 태스크마다 다른 프롬프트를 학습.
- 파인튜닝(model tuning) 과 multi task model tuning
- 후자는 SPoT 에서 사용한 같은 source task 의 mixture 로 전체 모델을 파인튜닝하고 그 후 각각 타겟 task 에 대해 파인튜닝한다. -> 일반 파인튜닝보다 좀 더 competitive.
Experiment
Set up
L : prompt length (실험에서는 L = 100 tokens)
E : embedding size
$ρ ∈ R^{L×E}$ : shared prompt 로, source 와 target PT 에 사용
“-longer tuning” : 기존 Prompt Tuning steps =30K
default steps = 2^18 = 262,144 사용
** source prompt tuning 의 경우, 처음 prompt 의 token embeddings 은 가장 일반적인 토큰 5,000개 로 sampled vocabulary 로 초기화 된다.
Source task
- single 비지도 학습 task
- 데이터의 청크에 프롬프트를 넣어서 학습.
- C4 dataset(이미 T5모델 pre training 에 사용됨. General purpose 프롬프트를 학습하는데 still 도움이 될 것이라고 생각.)
- single 지도학습 task
- MNLI(문장 level 분류문제) SquaD (QA) 를 source task 로.
- Multi task mixture
- GLUE와 SuperGLUE , NLI, paraphrasing/semantic similarity, semantic analysis, MRQA, common sence reasoning, MT, Summarization, NLG (GEM데이터셋) 등. 다양한 benchmark 사용.
- C4 + 55 labeled datasets 의 mixture 를 (다른 논문의) examples-proportional mixing strategy 를 이용하여 dataset size 가 k=2^19 개 가 되도록 한다.
- single 이 아니라 여러개 task 에 대해 단순히 서로 다른 task 를 섞는다.
Target task
GLUE와 SuperGLUE 사용.
Result
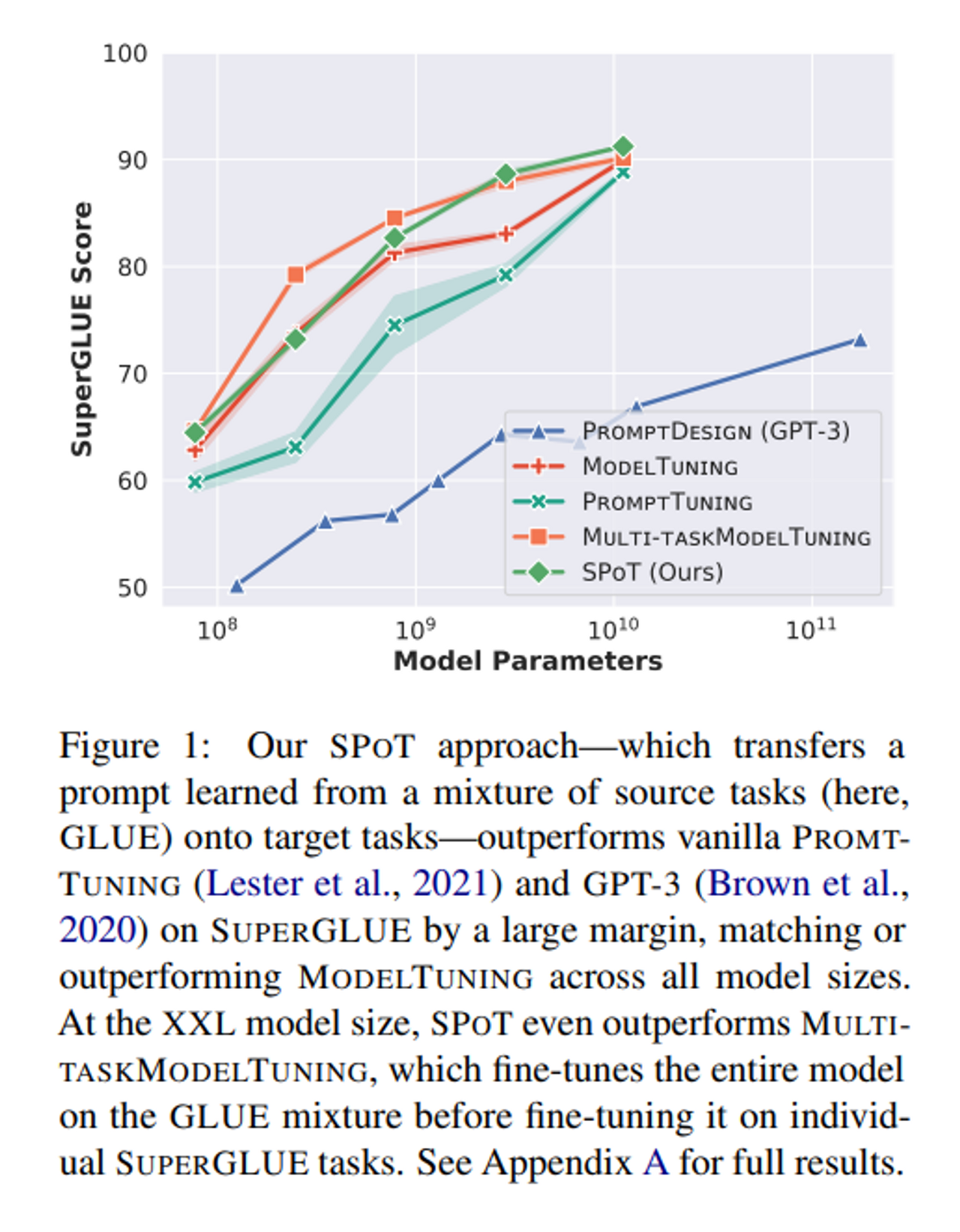
그림 1은 모델 크기에 따른 SUPER GLUE 결과를 보여준다.
이 때 source task 는 mixture of GLUE 이다.
일반 Prompt Tuning 은 모델 parameter 개수가 커질수록 좋은 성능을 확인할 수 있고 XXL 사이즈에서 일반 Fine tuning 성능과 거의 일치한다.
SPoT 은 일반 Prompt Tuning 과 Fine-tuning 사이 격차를 줄이면서 parameter efficient 함을 확인할 수 있다.
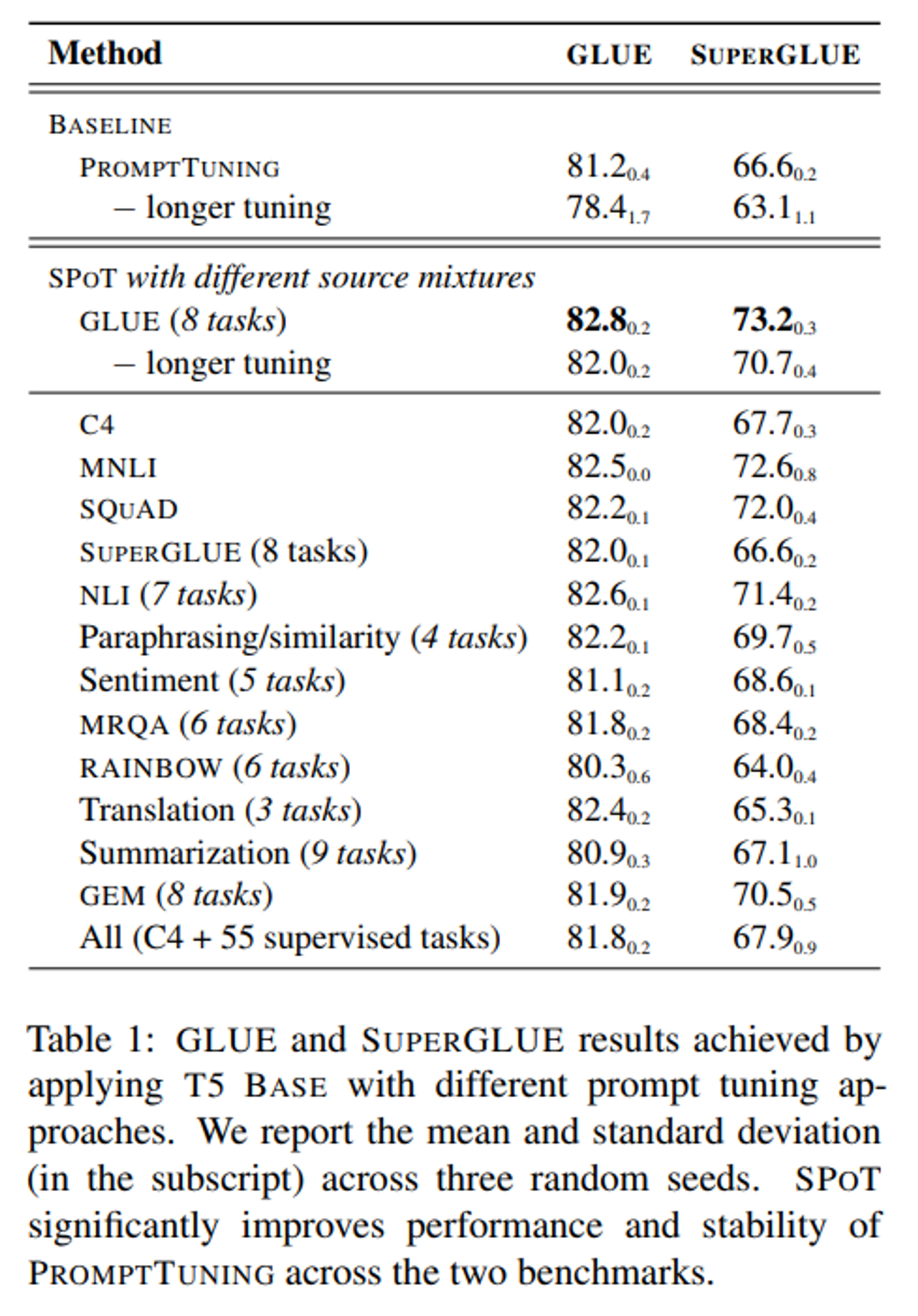
위 표는 T5 BASE를 사용한 GLUE 및 SuperGLUE 벤치마크 결과이다.
C4 데이터셋에서 Unsupervised 소스 프롬프트 튜닝(frozen model pre-training에서 사용했던 데이터셋)을 해도 상당한 개선이 이루어지며,
심지어 SUPERGLUE 작업에서 SUPERGLUE를 사용하는 것보다 더 나은 성능을 보인다.
Single source dataset 으로는 MNLI 또는 SQUAD를 사용하는 것이 좋음을 확인할 수 있다.
Predicting task transferability
Transfer 에 적합한 소스 작업을 선택하는 것이 중요하다.
그래서 논문에서는 어떤 source task 가 어떤 target task 에 transfer 되었을 때 좋은지 확인한다.
이 논문에서는 이를 위해서 task 임베딩을 통해 1. prompt transfer 로 인해 에러가 실제로 감소하였는지 확인하고 2. task 임베딩 간의 유사도를 파악하고 3. 마지막으로, source 와 target 사이의 유사도 와 에러 감소 사이의 관계성 에 대해 확인한다.

16개의 source datasets와 10개의 target datasets 연구.
가능한 160개의 source-target 쌍을 모두 고려해서 각 source task에서 각 target task 으로 transfer를 수행한다.
target tasks 는 low-resource tasks (훈련 예시 10,000개 미만)을 사용한다.
T5 BASE 사용.
Prompt Transfer 로 인한 에러 감소
전반적으로 prompt transfer 는 성능 향상을 얻음을 확인
💡 Relative Error Reduction (m1_error - m2_error) / m1_error * 100.0 m1 = model 1, m2 = model2 일 때, 모델1 에 비해 모델2 가 “얼마나 Error 를 감소시키는지” 계산한다.
MNLI(Multi-NLI : 문장간의 관계성 T,F,N 를 확인) → CB 가 가장 큰 에러감소 relative error reduction 인 58.9% (average score 92.7 → 97.0)를 얻음.
MNLI → COPA (29.1%)
RECORD → WSC (20.0%).
전반적으로 prompt transfer 는 성능 향상 (붉은색)을 얻음을 확인
주로, source 와 target task 사이 비슷하거나 MNLI 같은 문장 간 의미를 알아보는 task 가 source task로 유리.
하지만 상대적으로 서로 다른 task 간에도 transferaility 가 높을 수 있음을 확인하였다.
Prompt 를 통한 task similarity 정의
특정 task 를 Prompt Tuning 할때 만 prompt parameter 가 업데이트 되기 때문에 이 학습된 prompt 를 task-specific knowledge라고 할 수 있다.
그래서 이 task prompts 를 task 임베딩으로 해석하여 각 task 끼리의 유사도를 측정하고 이 유사도와 성능 향상 사이의 관계를 알아본다.
COSINE SIMILARITY OF AVERAGE TOKENS:
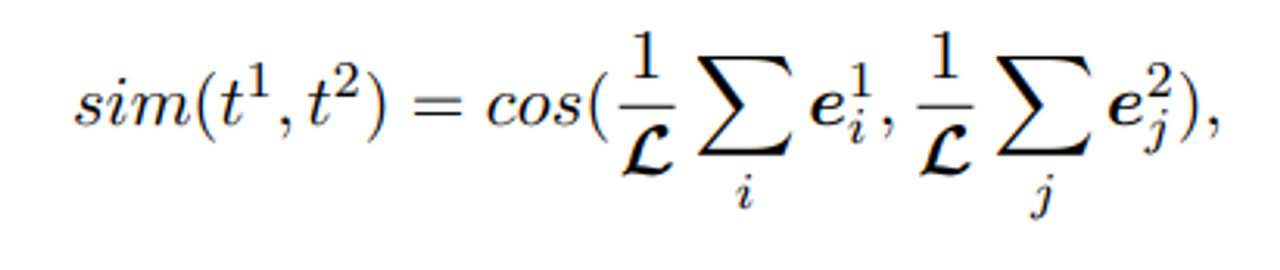
프롬프트 토큰들의 average pooled 값을 cos sim 계산하여 사용
-> 유사도를 사용하는 방법 중 이 논문에서는 다른 방법도 사용했는데, PER-TOKEN AVERAGE COSINE SIMILARITY 은 위의 방법보다 덜 유효하여 분석에 사용하지 않았다.

위 그림은 hierarchically-clustered heatmap 인데,
왜 클러스터링이냐면 : QA (SQUAD, RECORD, and DROP; MULTIRC and BOOLQ), sentiment analysis (YELP-2, SST-2, and CR), NLI (MNLI and CB; DOCNLI and RTE), semantic similarity (STS-B and CXC), paraphrasing (MRPC and QQP), and commonsense reasoning (WINOGRANDE, HELLASWAG, and COSMOSQA) 비슷한 task 끼리 클러스터링 해놓음.
학습된 task 임베딩이 많은 intuitive task 관계성을 표현하는 것을 확인함.
→ 예를 들어 QNLI (Squad 데이터셋에서 만들어진 NLI(Natural language inference : ****hypothesis 에 대해 True False neutral 인지 파악) 데이터셋) 은 Squad 데이터셋이랑 밀접하지 않다.
→ RECORD(Reading Comprehension with Commonsense Reasoning Dataset: ****News article, 빈칸 query 와 answer text span 으로 이루어짐) → WSC(Winograd Schema Challenge: commonsense reasoning 인데 대명사가 무엇인지 맞추는 task) 도 관계성이 높음. → transferability 도 높았다.
이는 task embedding 이 domain similarity 보다 task type 에 더 민감함을 알 수 있다.
Similarity 를 통한 Transferability 예측
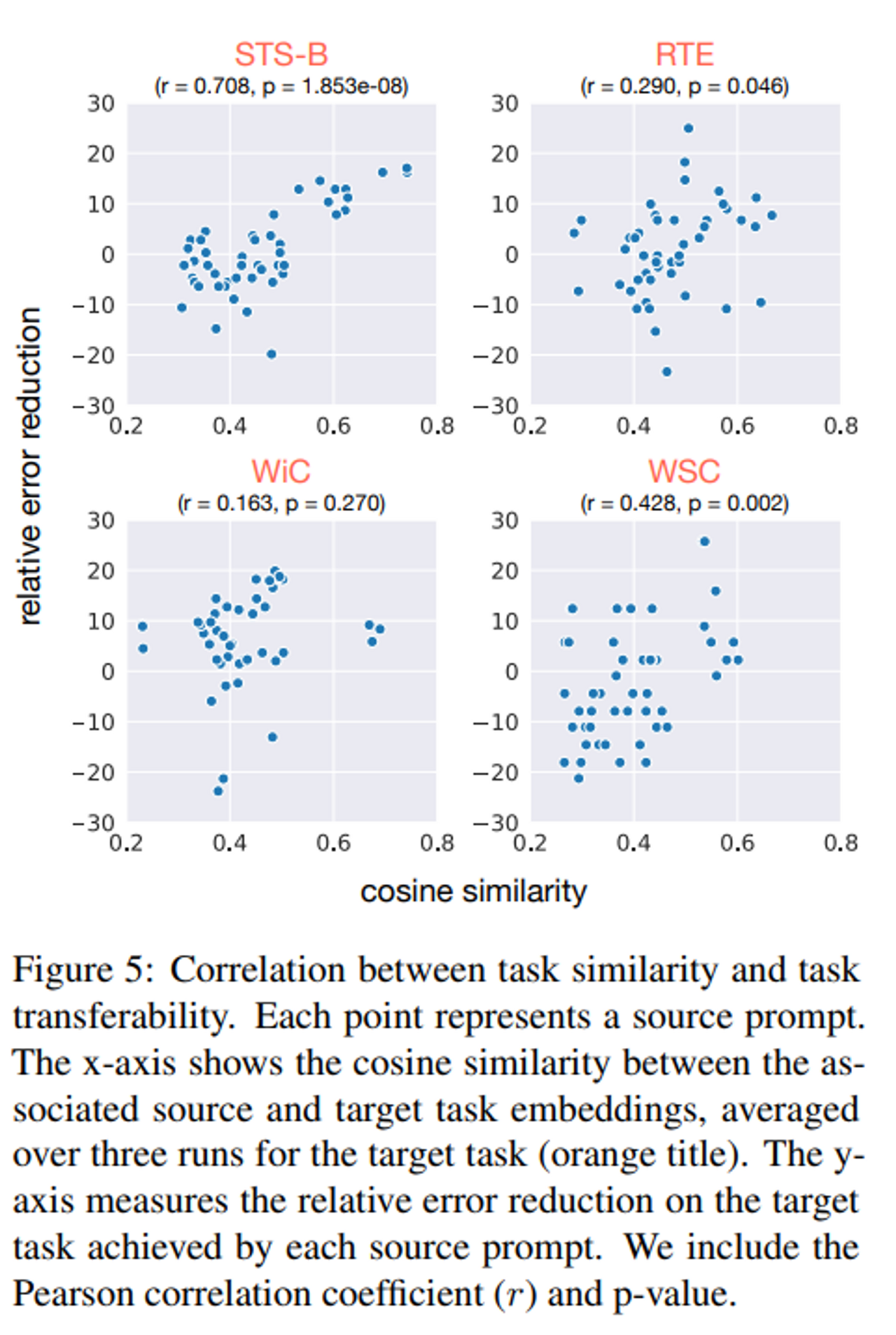
Figure 5 는 source task 와 target task 임베딩 사이의 similarity 에 따라 target task 에 대한 relative error reduction 의 correlation
10개 중에서 4개의 target task 에서 task embedding similarity 와 task transferability 사이 significant 한 positive correlation 을 확인하였다.
'LLM 관련 논문 정리' 카테고리의 다른 글
| LLAMA-2 from the ground up (0) | 2024.02.11 |
|---|---|
| SOLAR model paper (1) | 2024.01.13 |
| NEFTune: Noisy Embeddings Improve Instruction Fine-tuning (0) | 2023.11.15 |
| CLM, MLM, TLM 그리고 Seq2Seq (0) | 2023.10.30 |
| Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning (NIPS, 2208) (0) | 2023.09.30 |