
vLLM 이란 LLM 이 inference 와 serving 을 빠르게 할 수 있도록 하는 오픈소스 라이브러리이다.
PagedAttention 을 사용하여 어텐션의 key 와 value 를 효율적으로 관리한다.
모델 구조의 변환없이 기존 허깅페이스 Transformers 보다 24배 빠른 throughput 을 얻을 수 있었다.
📝 KV cache?
auto-regressive 모델은 이전 step 에서 생성된 token sequence 를 이용하여 다음 단계 출력을 예측하는 모델로, 주로 transformer decoder 모델이다. KV caching 은 디코더에서만 사용된다. auto-regressive 에서 이전 토큰의 attention 연산이 반복되기 때문이다. KV cache 는 새로 생성된 토큰의 attention 계산만 할 수 있도록 한다.
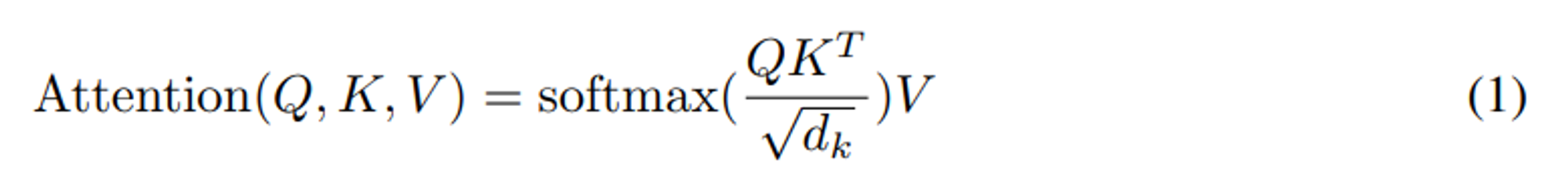
이 때 토큰을 생성할 때 계산되는 key 와 value 는 이전 step 에서 계산된 값이 쌓이면서 계산되기 때문에 이전 step 의 토큰을 다시 계산하지 않으려면 cache 에 저장해둬야 한다. 그래서 KV cache 가 필요하다. 아래 그림은 cache 가 어떻게 작동하는 지에 대한 그림이다.

cache 가 있을 때와 없을 때를 비교하는 그림이다. step 1에서 1번째 token (예를 들면 <sos> special token) 에 대해 attention 을 계산한다. 이후 다음 token 이 생성될 것이다.
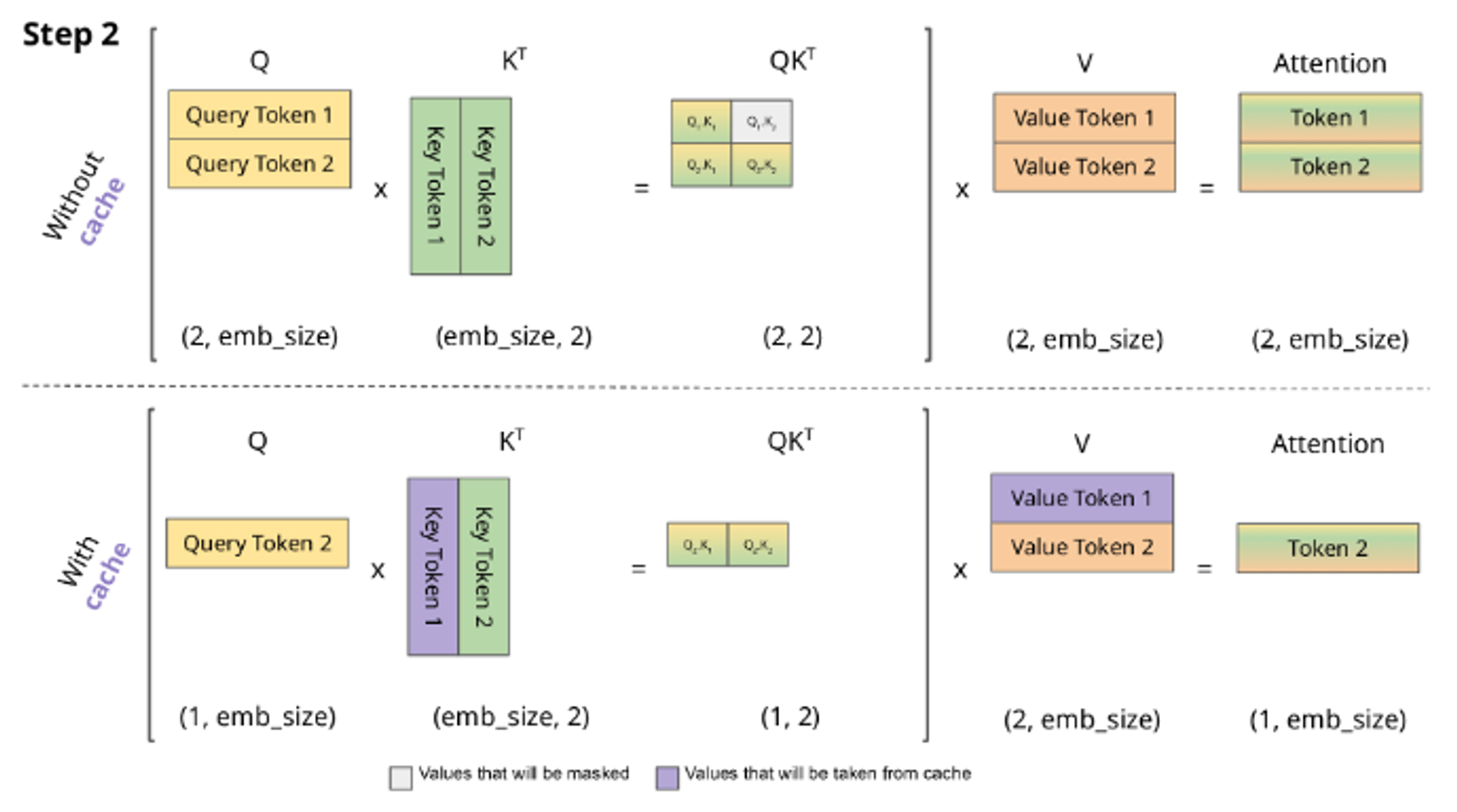
step 2 에서 cache 유무의 차이를 확인할 수 있다.
cache 가 없으면 query 가 쌓이면서 이전 step 에서 계산했던 W_k 행렬곱으로 key를 다시 계산해서 attention weight(key 와 query 를 내적한 값) 를 얻어야 한다. value 도 마찬가지이다. 그렇게 계산된 attention 은 이전 token 의 attention 이 합쳐진 우리가 흔히 아는 stack 된 구조를 가진다.
key 와 value 가 저장되면 이전 step 에서 계산된 query 값은 저장될 필요가 없다. 이전 query 토큰에 대한 값은 이미 계산되었기 때문에 새로 생성되는 토큰 token2 만 가지고 있으면 된다. 이렇게 token2 에 대한 attention 만 계산된다.
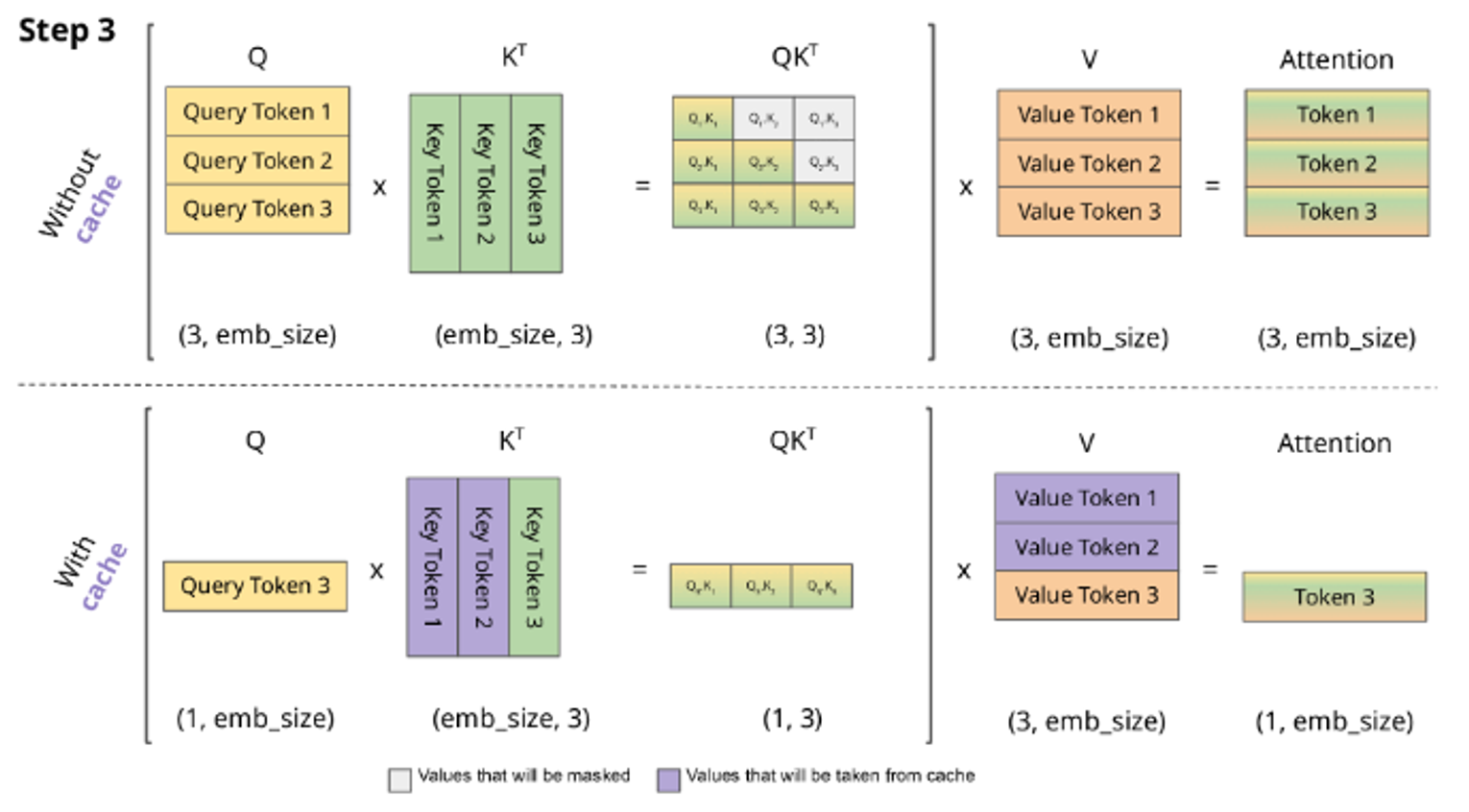
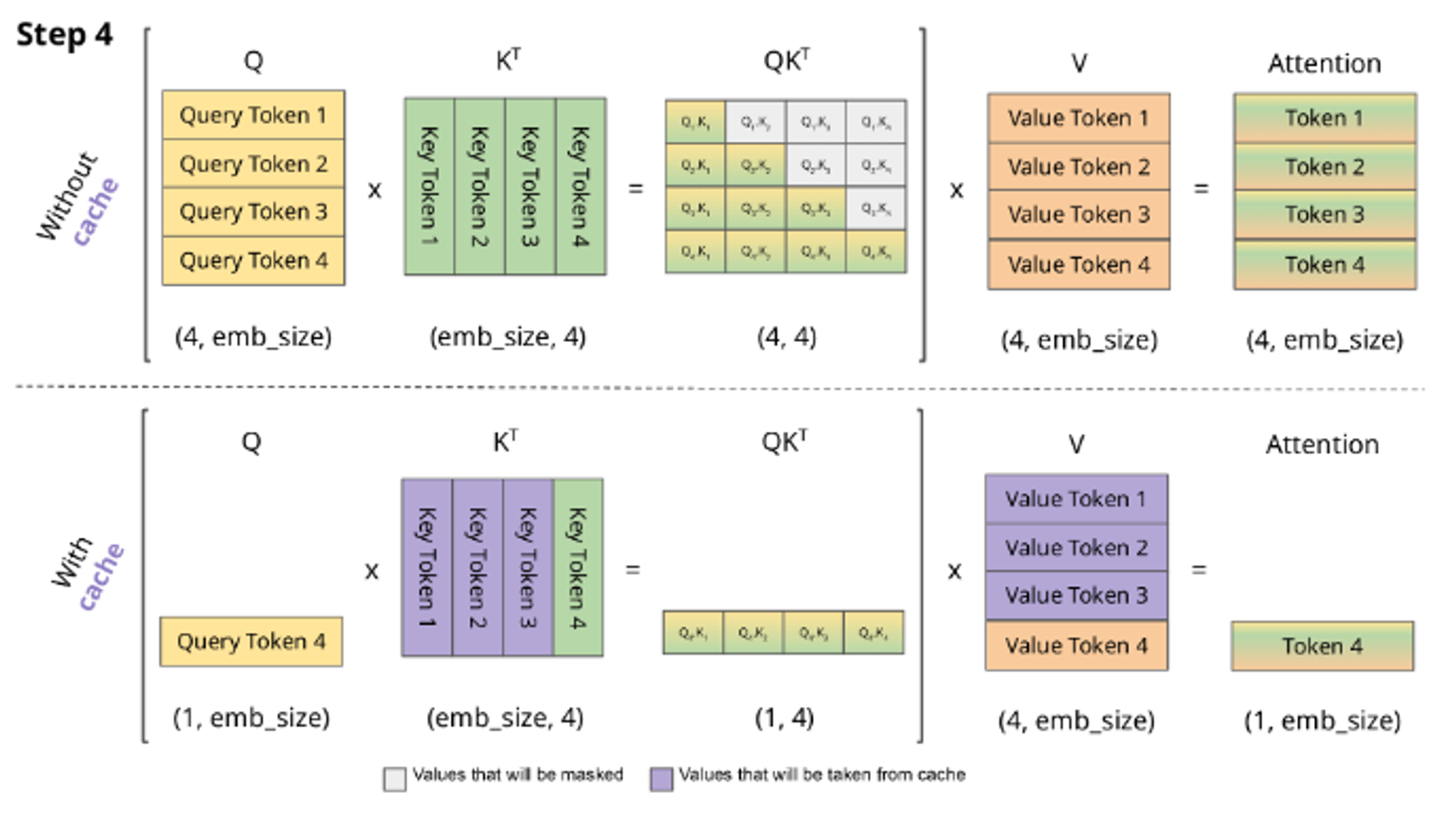
그래서 kv cache 는 W_k 와 W_v 로 계산된 값을 저장하는 역할을 한다.
그렇다면 KV cache 의 최적화는 왜 중요한가?
KV caching 을 사용하면 행렬곱셈은 훨신 빨라지지만 행렬 state 를 저장하기 때문에 많은 GPU VRAM 이 필요하다는 단점이 있다. 또한 context length 와 batch size 가 증가할수록 KV cache 요구량이 매우 증가한다.
# <https://medium.com/@joaolages/kv-caching-explained-276520203249> 참조
import numpy as np
import time
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2").to(device)
for use_cache in (True, False): # kv cache 사용여부
times = []
for _ in range(10): # measuring 10 generations
start = time.time()
model.generate(**tokenizer("What is KV caching?", return_tensors="pt").to(device), use_cache=use_cache, max_new_tokens=1000)
times.append(time.time() - start)
print(f"{'with' if use_cache else 'without'} KV caching: {round(np.mean(times), 3)} +- {round(np.std(times), 3)} seconds")
를 사용하였을 때 T4 gpu 조건에서 아래와 같은 차이가 난다는 것을 확인하였다고 한다.
with KV caching: 11.885 +- 0.272 seconds
without KV caching: 56.197 +- 1.855 seconds
PagedAttention
위에서 설명한 거처럼 kv cache 에서는 auto-regressive model 을 사용한 decoding 에서 같은 계산을 반복하지 않도록 attention key value 값을 저장한다.
그러므로 LLM 을 inference 할 때 메모리로 인해 병목현상이 생긴다.
kv cache 의 특징
- Large : 1개 sequence 에 대해 LLaMA-13B 모델에서 최대 1.7GB 를 잡아먹는다.
- Dynamic : sequence length 에 의존하기 때문에 매우 동적이고 예측하기 쉽지 않다. 그러므로 kv cache 를 효율적으로 관리하는 것은 어려운 문제이다.
기존 시스템은 fragmentation 와 over-reservation로 인해 60% – 80% 의 메모리 낭비를 일으키는 것으로 확인되었다.
이 문제를 해결하기 위해 vllm 에서는 PagedAttention을 사용하였다.
기존의 고정적인 attention 과 달리 PagedAttention 은 연속적인 key 와 value 를 비연속적인 memory 에 저장할 수 있다. 각 sequence 의 kv cache 를 블록으로 나누고 각 블록은 fixed 된 토큰 개수만큼의 key 와 value 를 저장하고 있다.
attetion 계산동안 PagedAttention kernel 은 이 블록을 효율적으로 identify 해서 가져온다.
block 은 메모리안에서 연속적일 필요가 없기 때문에 key 와 value 가 os 의 virtual memory 처럼 유연하게 처리할 수 있다. : block 은 page, token 은 byte , sequence 는 process 라고 생각할 수 있다.
시퀀스의 continuous logistic block 은 block table 을 통해 비연속적인 physical blocks 에 매핑된다. Physical 블록은 새 토큰이 생성될 때 마다 필요에 따라 할당된다.

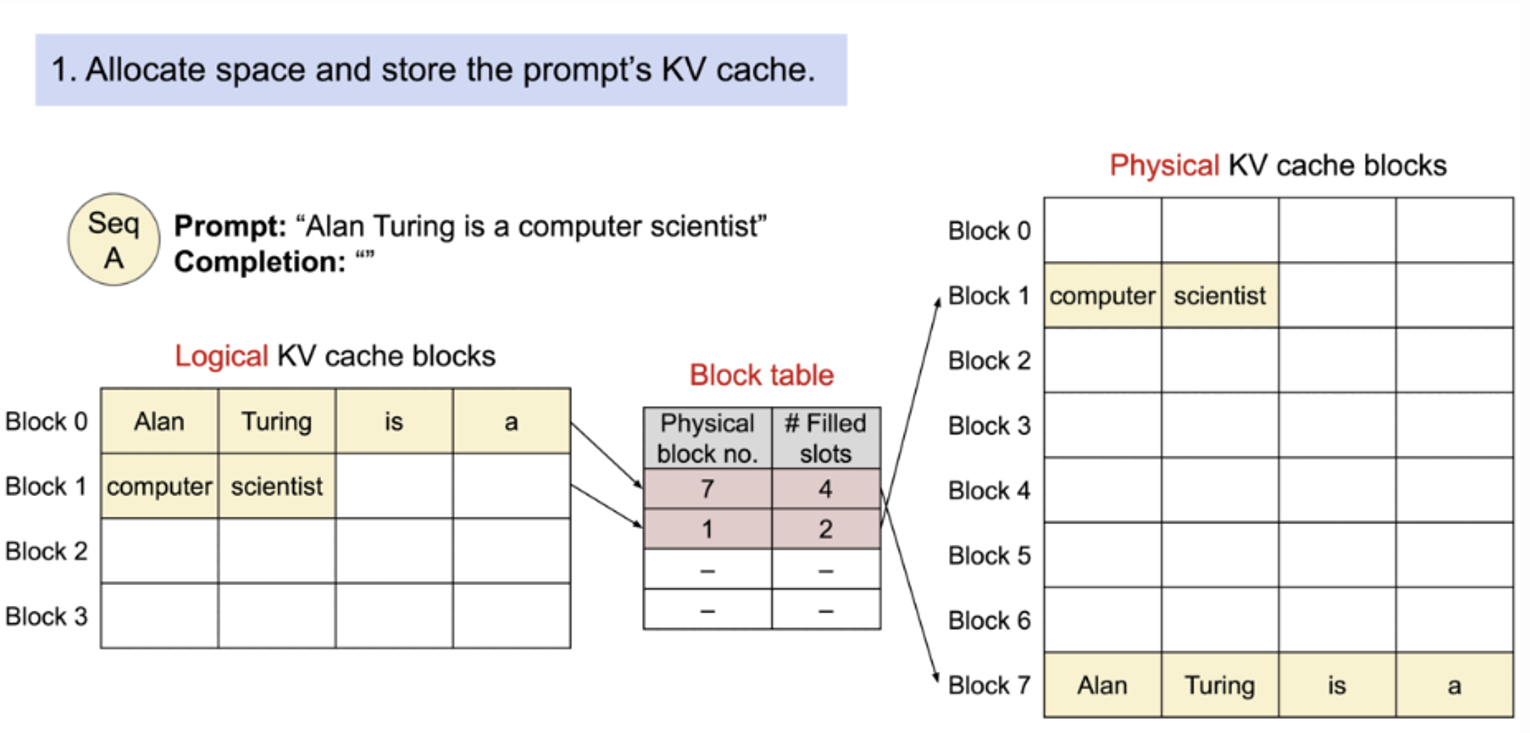


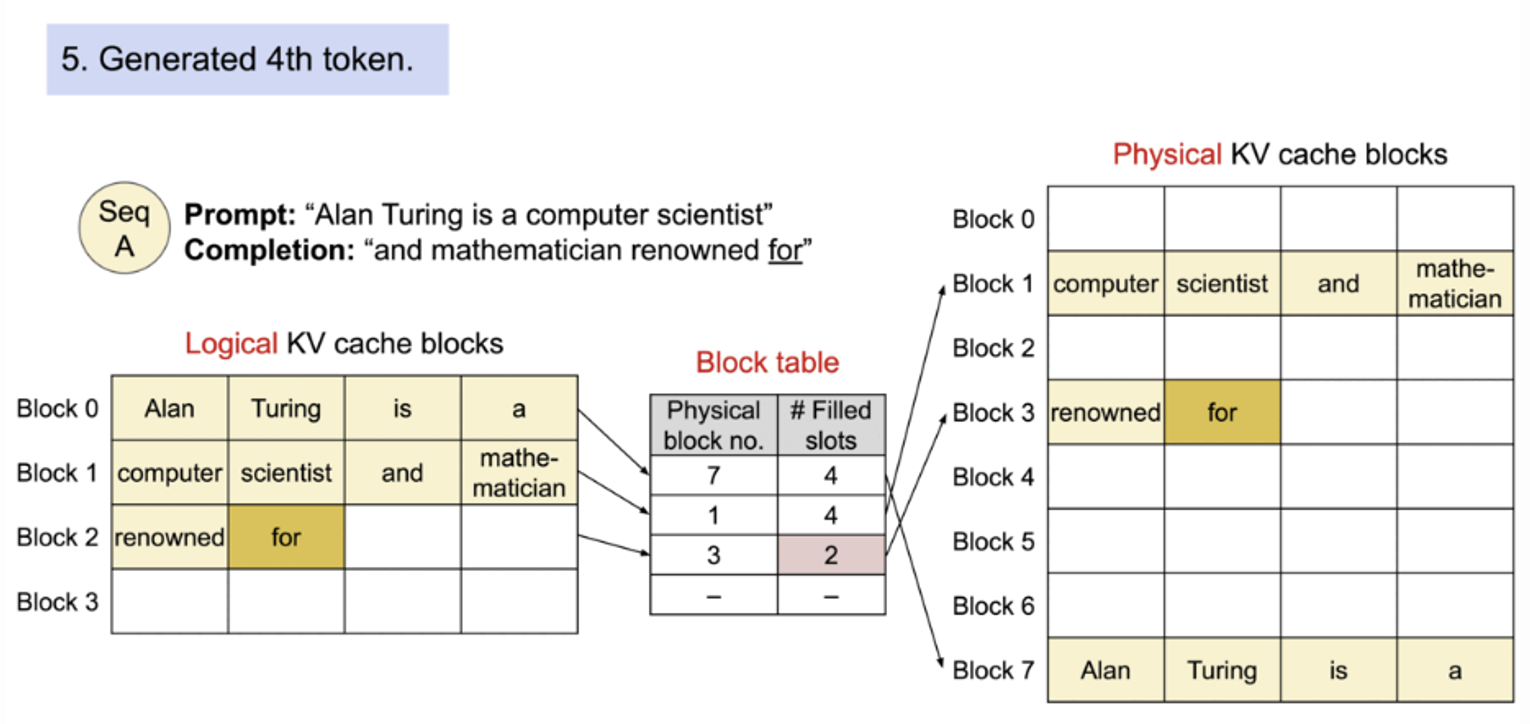
PagedAttention에서 메모리 낭비는 시퀀스의 마지막 블록에서만 발생한다. 그리고 실제 메모리 낭비는 4% 미만으로 거의 최적에 가까운 메모리 사용량을 얻을 수 있다. 이러한 메모리 효율성 향상은 시스템에서 더 많은 batch 를 한번에 처리할 수 있다.
PagedAttention 효율적인 메모리 공유라는 또 다른 주요 장점이 있다.
예를 들어 아래 그림과 같이 parallel sampling 에서는 동일한 프롬프트에서 여러 출력 시퀀스가 생성된다.
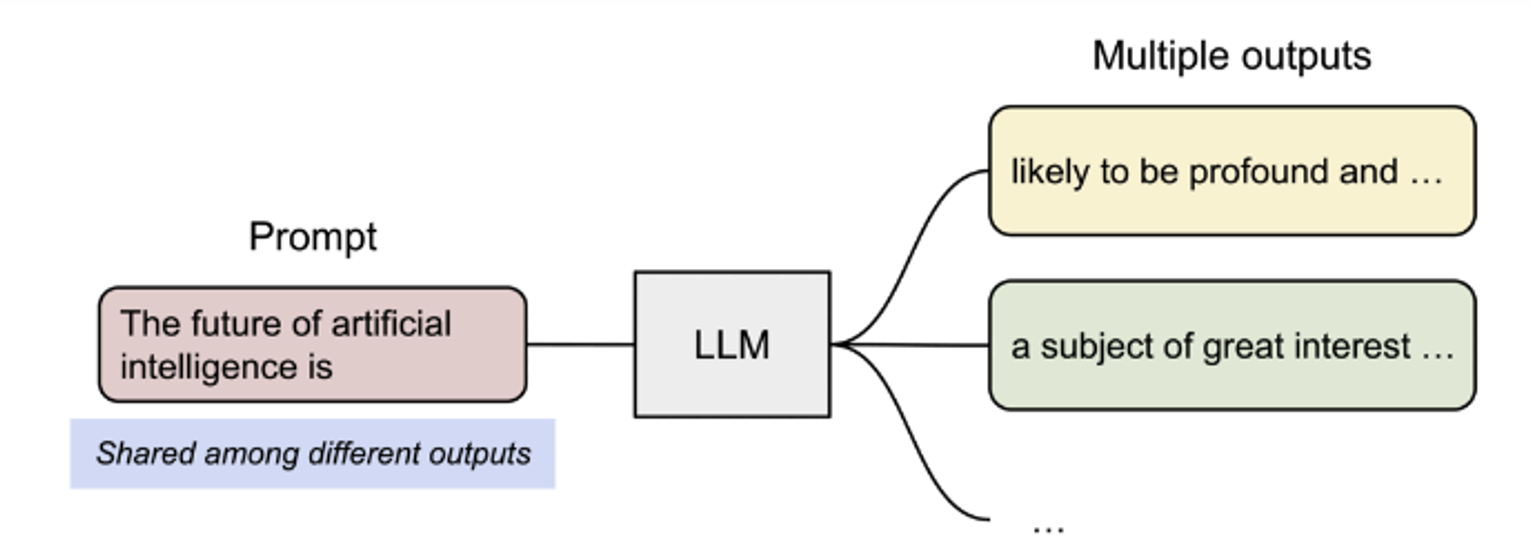
프롬프트에 대한 연산과 메모리를 출력 시퀀스 간에 공유할 수 있습니다.
PagedAttention에서 서로 다른 시퀀스에서 블록 테이블을 통해 logical blocks 를 같은 physical block에 매핑하여 (logical blocks) 메모리를 공유할 수 있다.
안전한 공유를 위해 PagedAttention은 physical blocks의 참조 횟수를 추적하고 Copy-on-Write mechanism 을 구현한다.
사용 방법
설치
$ pip install vllm
이후 Python script 에서는 간단하게 아래와 같이 사용할 수 있다.
from vllm import LLM
prompts = ["Hello, my name is", "The capital of France is"] # Sample prompts.
llm = LLM(model="lmsys/vicuna-7b-v1.3") # Create an LLM.
outputs = llm.generate(prompts) # Generate texts from the prompts.
https://github.com/vllm-project/vllm/blob/main/vllm/entrypoints/llm.py
vllm/vllm/entrypoints/llm.py at main · vllm-project/vllm
A high-throughput and memory-efficient inference and serving engine for LLMs - vllm-project/vllm
github.com
위는 LLM 코드이다.
Decode
하지만 위의 코드로는 다양한 decoding 방법을 적용할 수 없다.
vllm/vllm/sampling_params.py 의 SamplingParams 를 사용하면된다.
https://github.com/vllm-project/vllm/blob/main/vllm/sampling_params.py
vllm/vllm/sampling_params.py at main · vllm-project/vllm
A high-throughput and memory-efficient inference and serving engine for LLMs - vllm-project/vllm
github.com
위는 SamplingParams 코드로, 필요한 다른 세팅을 알 수 있다.
from vllm import SamplingParams
sampling_params = SamplingParams(
top_k=50,
top_p=0.9,
temperature = 0.8,
)
outputs = llm.generate(prompts, sampling_params)
Device 정의
vllm 에서는 gpu 를 사용할 때 따로 to(device) 처럼 사용하지 않는다. 아래와 같이 설정해준다.
os.environ["CUDA_VISIBLE_DEVICES"] = '1'
Reference
https://blog.vllm.ai/2023/06/20/vllm.html
https://medium.com/@joaolages/kv-caching-explained-276520203249
https://tech.scatterlab.co.kr/vllm-implementation-details/
https://cloud.google.com/kubernetes-engine/docs/tutorials/serve-gemma-gpu-vllm?hl=ko
'Python 및 Torch 코딩 이모저모' 카테고리의 다른 글
| Git 이용법 1 (0) | 2024.11.11 |
|---|---|
| Tmux (혹은 일반 터미널) TIMEOUT (0) | 2024.10.22 |
| Pdb 디버깅 (0) | 2024.03.09 |
| HuggingFace Trainer 학습이 중간에 끊겼을 때 (0) | 2024.02.25 |
| HuggingFace OSError: You are trying to access a gated repo.Make sure to request access at 에러 (0) | 2024.01.24 |
vLLM 이란 LLM 이 inference 와 serving 을 빠르게 할 수 있도록 하는 오픈소스 라이브러리이다.
PagedAttention 을 사용하여 어텐션의 key 와 value 를 효율적으로 관리한다.
모델 구조의 변환없이 기존 허깅페이스 Transformers 보다 24배 빠른 throughput 을 얻을 수 있었다.
📝 KV cache?
auto-regressive 모델은 이전 step 에서 생성된 token sequence 를 이용하여 다음 단계 출력을 예측하는 모델로, 주로 transformer decoder 모델이다. KV caching 은 디코더에서만 사용된다. auto-regressive 에서 이전 토큰의 attention 연산이 반복되기 때문이다. KV cache 는 새로 생성된 토큰의 attention 계산만 할 수 있도록 한다.
이 때 토큰을 생성할 때 계산되는 key 와 value 는 이전 step 에서 계산된 값이 쌓이면서 계산되기 때문에 이전 step 의 토큰을 다시 계산하지 않으려면 cache 에 저장해둬야 한다. 그래서 KV cache 가 필요하다. 아래 그림은 cache 가 어떻게 작동하는 지에 대한 그림이다.
cache 가 있을 때와 없을 때를 비교하는 그림이다. step 1에서 1번째 token (예를 들면 <sos> special token) 에 대해 attention 을 계산한다. 이후 다음 token 이 생성될 것이다.
step 2 에서 cache 유무의 차이를 확인할 수 있다.
cache 가 없으면 query 가 쌓이면서 이전 step 에서 계산했던 W_k 행렬곱으로 key를 다시 계산해서 attention weight(key 와 query 를 내적한 값) 를 얻어야 한다. value 도 마찬가지이다. 그렇게 계산된 attention 은 이전 token 의 attention 이 합쳐진 우리가 흔히 아는 stack 된 구조를 가진다.
key 와 value 가 저장되면 이전 step 에서 계산된 query 값은 저장될 필요가 없다. 이전 query 토큰에 대한 값은 이미 계산되었기 때문에 새로 생성되는 토큰 token2 만 가지고 있으면 된다. 이렇게 token2 에 대한 attention 만 계산된다.
그래서 kv cache 는 W_k 와 W_v 로 계산된 값을 저장하는 역할을 한다.
그렇다면 KV cache 의 최적화는 왜 중요한가?
KV caching 을 사용하면 행렬곱셈은 훨신 빨라지지만 행렬 state 를 저장하기 때문에 많은 GPU VRAM 이 필요하다는 단점이 있다. 또한 context length 와 batch size 가 증가할수록 KV cache 요구량이 매우 증가한다.
# <https://medium.com/@joaolages/kv-caching-explained-276520203249> 참조
import numpy as np
import time
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2").to(device)
for use_cache in (True, False): # kv cache 사용여부
times = []
for _ in range(10): # measuring 10 generations
start = time.time()
model.generate(**tokenizer("What is KV caching?", return_tensors="pt").to(device), use_cache=use_cache, max_new_tokens=1000)
times.append(time.time() - start)
print(f"{'with' if use_cache else 'without'} KV caching: {round(np.mean(times), 3)} +- {round(np.std(times), 3)} seconds")
를 사용하였을 때 T4 gpu 조건에서 아래와 같은 차이가 난다는 것을 확인하였다고 한다.
with KV caching: 11.885 +- 0.272 seconds
without KV caching: 56.197 +- 1.855 seconds
PagedAttention
위에서 설명한 거처럼 kv cache 에서는 auto-regressive model 을 사용한 decoding 에서 같은 계산을 반복하지 않도록 attention key value 값을 저장한다.
그러므로 LLM 을 inference 할 때 메모리로 인해 병목현상이 생긴다.
kv cache 의 특징
- Large : 1개 sequence 에 대해 LLaMA-13B 모델에서 최대 1.7GB 를 잡아먹는다.
- Dynamic : sequence length 에 의존하기 때문에 매우 동적이고 예측하기 쉽지 않다. 그러므로 kv cache 를 효율적으로 관리하는 것은 어려운 문제이다.
기존 시스템은 fragmentation 와 over-reservation로 인해 60% – 80% 의 메모리 낭비를 일으키는 것으로 확인되었다.
이 문제를 해결하기 위해 vllm 에서는 PagedAttention을 사용하였다.
기존의 고정적인 attention 과 달리 PagedAttention 은 연속적인 key 와 value 를 비연속적인 memory 에 저장할 수 있다. 각 sequence 의 kv cache 를 블록으로 나누고 각 블록은 fixed 된 토큰 개수만큼의 key 와 value 를 저장하고 있다.
attetion 계산동안 PagedAttention kernel 은 이 블록을 효율적으로 identify 해서 가져온다.
block 은 메모리안에서 연속적일 필요가 없기 때문에 key 와 value 가 os 의 virtual memory 처럼 유연하게 처리할 수 있다. : block 은 page, token 은 byte , sequence 는 process 라고 생각할 수 있다.
시퀀스의 continuous logistic block 은 block table 을 통해 비연속적인 physical blocks 에 매핑된다. Physical 블록은 새 토큰이 생성될 때 마다 필요에 따라 할당된다.
PagedAttention에서 메모리 낭비는 시퀀스의 마지막 블록에서만 발생한다. 그리고 실제 메모리 낭비는 4% 미만으로 거의 최적에 가까운 메모리 사용량을 얻을 수 있다. 이러한 메모리 효율성 향상은 시스템에서 더 많은 batch 를 한번에 처리할 수 있다.
PagedAttention 효율적인 메모리 공유라는 또 다른 주요 장점이 있다.
예를 들어 아래 그림과 같이 parallel sampling 에서는 동일한 프롬프트에서 여러 출력 시퀀스가 생성된다.
프롬프트에 대한 연산과 메모리를 출력 시퀀스 간에 공유할 수 있습니다.
PagedAttention에서 서로 다른 시퀀스에서 블록 테이블을 통해 logical blocks 를 같은 physical block에 매핑하여 (logical blocks) 메모리를 공유할 수 있다.
안전한 공유를 위해 PagedAttention은 physical blocks의 참조 횟수를 추적하고 Copy-on-Write mechanism 을 구현한다.
사용 방법
설치
$ pip install vllm
이후 Python script 에서는 간단하게 아래와 같이 사용할 수 있다.
from vllm import LLM
prompts = ["Hello, my name is", "The capital of France is"] # Sample prompts.
llm = LLM(model="lmsys/vicuna-7b-v1.3") # Create an LLM.
outputs = llm.generate(prompts) # Generate texts from the prompts.
https://github.com/vllm-project/vllm/blob/main/vllm/entrypoints/llm.py
vllm/vllm/entrypoints/llm.py at main · vllm-project/vllm
A high-throughput and memory-efficient inference and serving engine for LLMs - vllm-project/vllm
github.com
위는 LLM 코드이다.
Decode
하지만 위의 코드로는 다양한 decoding 방법을 적용할 수 없다.
vllm/vllm/sampling_params.py 의 SamplingParams 를 사용하면된다.
https://github.com/vllm-project/vllm/blob/main/vllm/sampling_params.py
vllm/vllm/sampling_params.py at main · vllm-project/vllm
A high-throughput and memory-efficient inference and serving engine for LLMs - vllm-project/vllm
github.com
위는 SamplingParams 코드로, 필요한 다른 세팅을 알 수 있다.
from vllm import SamplingParams
sampling_params = SamplingParams(
top_k=50,
top_p=0.9,
temperature = 0.8,
)
outputs = llm.generate(prompts, sampling_params)
Device 정의
vllm 에서는 gpu 를 사용할 때 따로 to(device) 처럼 사용하지 않는다. 아래와 같이 설정해준다.
os.environ["CUDA_VISIBLE_DEVICES"] = '1'
Reference
https://blog.vllm.ai/2023/06/20/vllm.html
https://medium.com/@joaolages/kv-caching-explained-276520203249
https://tech.scatterlab.co.kr/vllm-implementation-details/
https://cloud.google.com/kubernetes-engine/docs/tutorials/serve-gemma-gpu-vllm?hl=ko
'Python 및 Torch 코딩 이모저모' 카테고리의 다른 글
| Git 이용법 1 (0) | 2024.11.11 |
|---|---|
| Tmux (혹은 일반 터미널) TIMEOUT (0) | 2024.10.22 |
| Pdb 디버깅 (0) | 2024.03.09 |
| HuggingFace Trainer 학습이 중간에 끊겼을 때 (0) | 2024.02.25 |
| HuggingFace OSError: You are trying to access a gated repo.Make sure to request access at 에러 (0) | 2024.01.24 |