
E5-V: Universal Embeddings with Multimodal Large Language Models
https://arxiv.org/pdf/2407.12580
Abstract

** Multimodal large language models (MLLMs)** 은 비전 및 언어 이해에 매우 큰 발전이지만, 이를 이용한 멀티모달 정보 를 표현하는 데에는 (임베딩) 많은 연구가 이루어지지 않았다.
이 논문에서는 새로운 구조인 E5-V 를 제안하여 **universal multimodal embeddings** 을 하도록 한다.
이 방법은 파인튜닝 없이도 서로 다른 modality(이미지나 텍스트 등) 의 input 사이 갭을 줄일 수 있다. 이는 이미지-텍스트 pair 로 학습하는 기존의 멀티모달 학습보다 training costs를 95% 까지 줄였고, 멀티모달 학습데이터 수집 필요를 없앴다.
2. Related Work
2.1 Multimodal Large Language Models
MLLMs 는 멀티모달 LLM 이다. BLIP, KOSMOS, LLaMA-Adapter, LLaVA 등
2.2 Multimodal Embeddings
CLIP 은 multimodal embeddings 의 시초다. text-image retrieval 에서 좋은 성능을 나타낸다.
이미지와 텍스트에 대해 서로 다른 인코더를 사용하여 contrastive 학습으로 align 한다.
CLIP 은 모델 framework 로 인해 몇 가지 한계가 있는데, 첫 번째는 CLIP 의 텍스트 인코더가 짧은 이미지 캡션만 학습해서 복잡한 텍스트에 대해서는 low capacity를 보인다는 것이다. 그래서 긴 문장에 대한 검색은 성능의 한계가 있다.
또한 서로 분리되어있는 이미지와 텍스트 인코더 때문에 composed image retrieval 과 같은 뭐지,, 엄청 인접해있는? 관련있는 이미지-텍스트에 대해서는 성능이 낮다.
universal multimodal embedding 태스크에는 UNIIR (CLIP을 파인튜닝한,) 라는 연구가 있다. visual 과 텍스트 정보를 fuse 한다.
또한 VISTA 나 UniVL-DR는 텍스트 인코더에 CLIP 출력값을 더 넣어준다. 하지만 이는 다른 단점도 존재한다. (생략)
3. E5-V
3.1 Unifying Multimodal Embeddings
CLIP 과 같은 모달리티 임베딩 연구들에서는 이미지와 텍스트 사이에 modality gap 이 존재하는데 이는 성능에 안좋은 영향을 준다고 설명한다. 비슷하게 이 논문에서는 MLLM 에서 비슷한 문제점이 나타나는 것을 확인하였다.

위 그림 3.a 는 COCO 데이터셋의 이미지-캡션을 LLaVA-NeXT-8B 모델의 last token embeddings을 뽑아 PCA 로 표한한 그림이다.
CLIP 과 비교하였을 때 MLLM 은 이미지와 텍스트를 같은 인코더로 표현하긴 하지만 임베딩은 modality gap이 있음을 확인하였다.
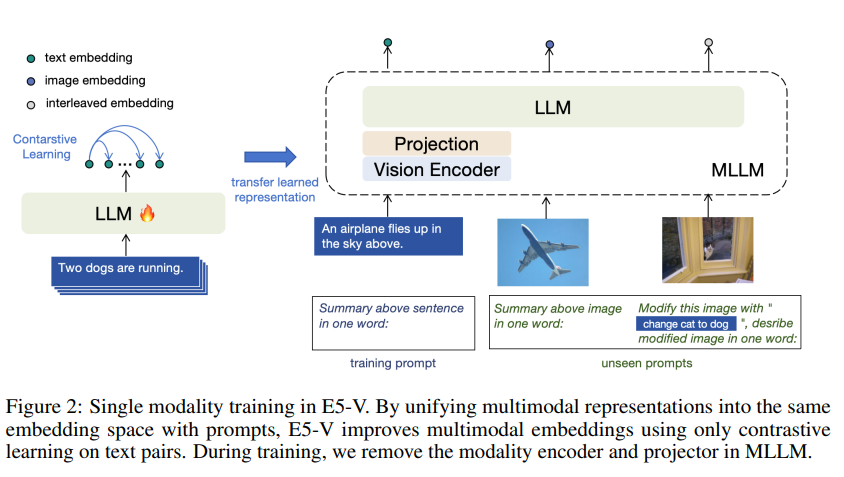
위 그림은 멀티 모달 임베딩을 위해 E5-V를 Single modality를 학습시킨 것이다. 프롬프트로 멀티모달 표현을 같은 임베딩 공간에 표현한다.
멀티모달 임베딩을 unify 하기 위해 MLLM 에 prompt-based 표현 방법을 제안한다.
즉, 멀티모달 입력을 단어로 표현하도록 MLLM 에게 inst 를 주는 것이다.
이 때 아래와 같은 프롬프트를 사용한다.
`<text> \n Summary of the above sentence in one word:`
`<image> \n Summary above image in one word:`
그림 3.b 를 보면 이렇게 프롬프트를 사용하여 이미지를 표현하면 텍스트와 이미지 사이 modality gap 을 없앨 수 있다.
프롬프트 디자인은 멀티모달 input 의 의미를 추출하는 부분과 이를 'in one word' 라는 표현을 사용하여 next token embeddings 에 의미를 압축하고 멀티모달 임베딩으로 통합한다.
3.2 Single Modality Training
멀티모달 임베딩을 학습하기 위해
임베딩에 modality gap 이 없기 때문에 텍스트 쌍에 대해서만 학습하여 단일 모달리티 표현 기능을 멀티 모달로 변환할 수 있다.
그러므로 멀티모달 training data 나 이미지와 합성된 input 에 의존하지 않는다.
E5-V 는 MLLMs을 contrastive learning 을 사용하여 텍스트 쌍을 학습한다. 학습 동안은 visual 입력이 들어가지 않고, MLLM 에서 modality encoder 와 projector 를 뺀 LLM 부분만 학습시킨다.
멀티모달 데이터셋과 관련없는 NLI dataset의 sentence pairs (x_i, x_i^+, x_i^−) 를 사용한다. 각각 input, pos, neg 이다.
위에 있는 프롬프트인 `<text> \nSummary above sentence in one word:` 를 사용하여 위 의 sentence pair 를 (hi, h+i, h−i) 임베딩으로 바꾼다.
그리고 아래 objective 식으로 나타낼 수 있다.

위 식에서 τ = temperature hyperparameter, N = batch size
멀티모달 학습과 비교하여 single modality training은 멀티모달 검색 task 에서 더 좋은 성능을 얻고, 학습 cost 도 훨신 적었다.(Table 7)
-----
** 학습에 사용한 Dataset : Simcse: Simple contrastive learning of sentence embeddings.

-----
4. Experiments
E5-v 의 backbone 으로 LLaMA-3 8B 를 기반으로 한 LLaVA-NeXT-8B를 사용했고, CLIP ViT-L 를 visual encoder 로 사용했다.
QLora 사용.
contrastive learning 에서는 마지막 token 임베딩을 임베딩으로 사용.
4.1 Text-Image Retrieval
zero-shot image 및 text retrieval

Flickr30K 와 COCO 벤치마크 데이터셋을 사용하여
* coco dataset : 330K 이미지 데이터셋, object detection, caption 등 데이터셋
* Flickr30K : 위와 비슷한 bb 와 caption이 있는 이미지 데이터셋