
https://arxiv.org/pdf/2304.08485
많이 사용하는 비전-언어모델 튜닝에 많이 사용된다.
Abstract
machine 이 만들어낸 instruction following 데이터셋은 새로운 task 에서 zero shot 성능을 강화할 수 있었지만, multi-modal 분야에서는 비교적 덜 연구되어왔다.
이 논문에서는 처음으로 language-only GPT-4 모델을 이용하여 언어-이미지 멀티모달 instruction 데이터셋을 생성한다.
이 생성된 데이터를 사용하여 LLaVA: Large Language and Vision Assistant 를 소개한다. 이는 end-to-end로, 학습된 언어모델에 vision encoder 를 연결하여 general-purpose 비전-언어모델을 만든다.
평가를 위해 2가지 evaluation benchmark 를 만들었다.
GPT-4 와 비교하여 꽤 좋은 실험 결과를 얻었다. 생성한 visual instruction tuning data, our model, 와 code 는 public 이다.
3. GPT-assisted Visual Instruction Data Generation

GPT 를 프롬프팅하기 위해 context 로 이미지 설명 캡션이랑 bounding box 좌표가 컨텍스트로 주어진다.
그리고 그에 대한 3가지 response 를 얻는다. GPT 에서는 이미지를 따로 주지는 않는다.**
4. Visual Inst Tuning
4.1 구조
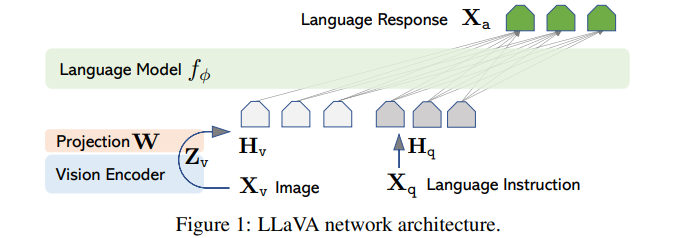
LLM 모델로는 Vicuna fϕ(·) 를 사용,
Xv 는 이미지 input 으로, visual encoder 로는 CLIP 의 ViT-L/14 를 사용. => Zv = g(Xv)
여기서도 text embedding space 에 이미지 임베딩을 연결하기 위해 linear layer W를 사용한다.

Hv 는 visual token 이다. (하지만 기본적인 linear layer 말고 더 복잡한 매핑을 할 수 있다, future work)
4.2 Training

이미지 인풋 Xv 에 대한 멀티턴 대화 데이터 (X1q, X1a, · · · , XTq, XTa) 를 생성한다. (T 는 멀티턴 total 개수)
멀티턴의 모든 답변을 assistant 의 response 로 처리하고 t번째 Xt_instruct = instruction 을 아래 식과 같이 정리한다.

이는 table 2에서 설명한 multi-modal instruction 시퀀스의 통합 형식이다.
기존의 auto-regressive 학습을 통해 LLM 을 instruction-tuning 한다.
길이 L 인 타겟 Xa 에 대한 probability 는 아래 식과 같다. θ 는 trainable parameter,

** 위 그림 설명 : 2 turn conversation 에 대한 설명이고, 은 '###' 이다. (Vicuna-v0 사용)
위 그림에서 초록색 부분만 loss 를 계산한다.
Stage 1: Pre-training for Feature Alignment
데이터셋은 CC3M 에서 595K 개의 image-text pairs 를 필터링한다. 이 데이터를 사용하여 3번의 데이터 생성 방법에 따라 instruction-following 데이터로 변환된다.
각 샘플은 single turn 대화로 처리된다.
X_instruct 를 만들기 위해 이미지 Xv와 질문 Xq 를 랜덤으로 샘플링한다. 이때 Xq는 assistant 에 이미지를 간단하게 설명해달라고 하는 언어 명령어이다. Xa 는 기존 데이터셋의 원래 있던 캡션으로, ground-truth 로 사용된다.
training 에서는 LLM 과 visual encoder 둘 다 freeze 하고 projection 파라미터 θ 만 학습시킨다.
Stage 2: Fine-tuning End-to-End
항상 visual encoder 는 freeze 하고, projection layer 와 LLM 만 업데이트한다.