
여러 개의 분류기의 prediction 을 결합하여 더 정확한 예측을 도출하는 기법이다.
원래는 Tree 에서 많이 사용되는 알고리즘
Evaluating the prediction of an ensemble typically requires more computation than evaluating the prediction of a single model.
- 앙상블기법의 예측력을 평가하기 위해서는 일반적으로 단일 모델의 예측을 평가하는 것보다 더 많은 계산이 필요합니다
Voting
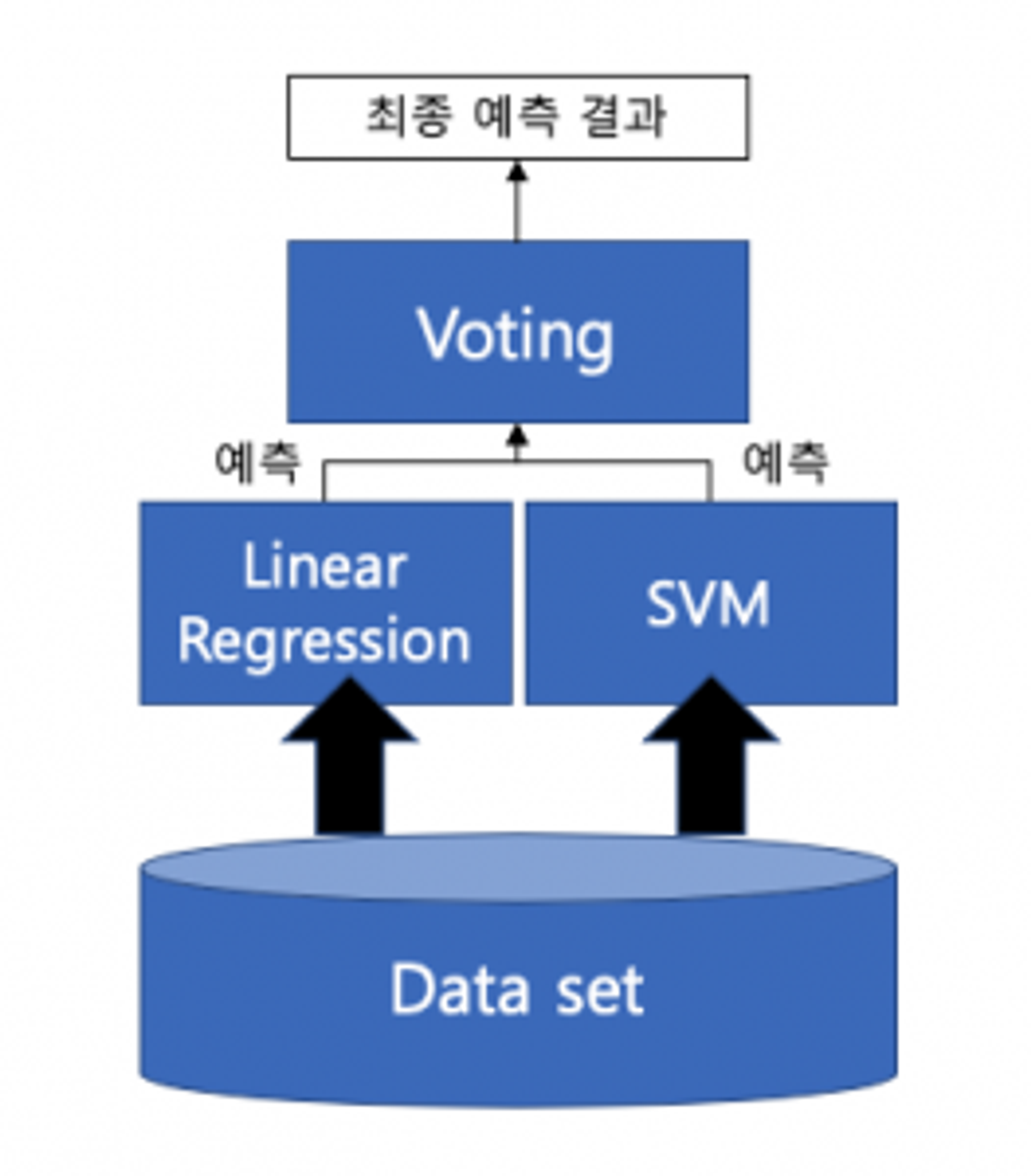
여러 개의 분류기 결과를 투표를 통해 최종 결과를 결정하는 방식.
즉, categorical data 일때 전체 모델 중 가장 많은 예측값을 최종 결과로 내놓음.
** Continuous Data 에서는 예측한 값의 평균 average 값을 최종결과로 사용한다.
Voting 은 Hard Voting 과 Soft Voting 방식으로 나뉜다.
- Hard Voting
- Soft Voting

Bagging (Bootstrap aggregating)

Boorstrap : 통계학에서 사용하는 용어로, random sampling 을 적용하는 방법 = 즉, 데이터 샘플링.
즉, 배깅이란 각 모델을 큰 데이터셋에서 (중복가능하게) 샘플링한 작은 학습데이터셋을 이용해 학습하고 bootstrap 을 하고 aggregate(집계)하여 사용.
inference 는 voting 을 사용한다.
높은 bias 의 underfitting 문제나 높은 variance 의 overfitting 문제를 해결할 수 있다.
배깅의 대표적 알고리즘으로 랜덤 포레스트(Random Forest)가 있다.
Boosting
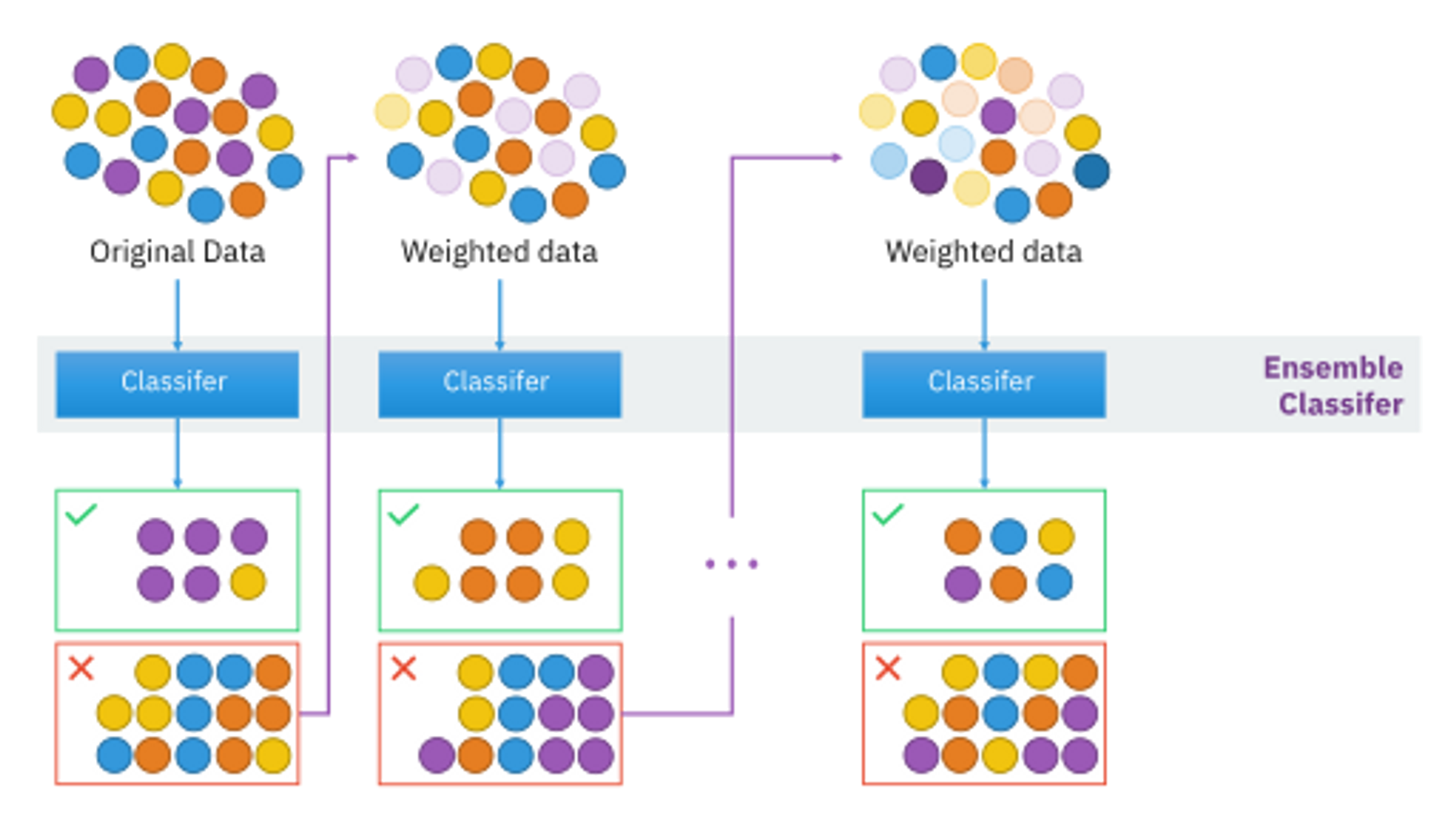
부스팅은 sequential 하게 사용되는 방법으로, 이전 모델에서 틀리게 예측한 학습 데이터의 가중치를 높여서 다음 모델에서 학습하는 방법이다.
먼저 학습된 모델의 결과를 바탕으로 개선해나가는 방향이다. 이 방법의 단점은 overfitting 의 가능성이 있다는 것이다.
마찬가지로 inference 는 voting 을 사용한다.
Stacking

개별 모델이 예측한 결과를 메타데이터로서 다시 사용하는 방법이다.
그러므로 Base Learner 와 Meta Learner (최종 모델) 가 필요하다.
'머신러닝 이모저모' 카테고리의 다른 글
| Precision 개념 (0) | 2024.02.18 |
|---|---|
| VScode 에서 tmux 사용하기 (0) | 2024.01.03 |
| UserWarning: CUDA initialization: Unexpected error from cudaGetDeviceCount() 에러 처리 (0) | 2024.01.03 |
| GPT-2 를 seq2seq 방식으로 학습시키기 (0) | 2023.12.07 |
| 딥러닝 에서의 Bayes’ Rule (1) | 2023.08.09 |