
Abstract 및 Introduction
LoRA 의 단점은 FT(full fine tuning) 과 비교해서 accuracy gap 이 있다는 것이다.
LoRA 와 FT 의 learning capacity 가 차이가 난다는 것인데,
이 이유를 weight decomposition analysis 를 제안하고 이를 통해 업데이트 패턴이 LoRA 와 FT 가 다르다는 점을 밝힌다.
DoRA 는 weight decomposition 을 통해 LoRA 의 장점인 inference latency overhead 가 없다는 점을 유지하면서 FT 의 성능을 능가할 수 있다.
실험결과에 따르면 commonsense reasoning (+3.4/+1.0 on LLaMA-7B/13B), 과 visual instruction tuning (+0.6 on LLaVA-7B) 와 image/video text understanding (+0.9/+1.9 on VL-BART) 에서 DoRA 가 LoRA 보다 지속적으로 좋은 성능을 얻었다.
2.Related Works
PEFT 에는 Adapter-based, Prompt-based, LoRA-based 가 있다.
전자의 두 카테고리는 initialization 에 민감하고, 모델의 인풋이나 구조를 변경해야한다는 단점이 있다.
또한 inference latency 도 발생시킨다.
LoRA (Hu et al., 2022) and its variants
하지만 LoRA 는 파인튜닝 동안 low rank 행렬을 사용하여 웨이트 대신 업데이트하고 이후 inference 때 merge 할 수 있다.
LoRA 는 좋은 학습 효과를 얻을 수 있기 때문에 variant 연구가 많이 진행되었는데,
예를 들면, SVD decomposition 을 적용하여 효율적인 업데이트를 위해 덜 중요한 singular value 를 프루닝하는 방법 (Zhang et al., 2023) 이 있고,
(Hyeon-Woo et al., 2022)는 low-rank Hadamard product 를 사용하여 federated learning(연합 학습?) 을 한다.
다른 (Qiu et al., 2023; Liu et al., 2023b) 연구는 orthogonal factorization를 사용하여 diffusion 모델을 파인튜닝한다.
weight tying 을 사용하여 학습가능한 파라미터를 더 줄이거나 (Renduchintala et al., 2023),
routing 함수를 사용하여 인벤토리에서 LoRA 의 다양한 combination 을 사용할 수 있도록 하는 (Ponti et al., 2022),
학습가능한 scaling 벡터를 구현하여 레이어 간에 공유된 frozen 된 random 행렬 쌍을 조정하는 VeRA (Kopiczko et al., 2024) 연구 등이 있다.
3. Pattern Analysis of LoRA and FT
3.1. Low rank Adaptation (LoRA) 설명
LoRA 는 파인 튜닝 중 weight update 는 low intrinsic rank 를 가진다는 가정하에 2개의 low rank 행렬 AB 를 사용하여 업데이트한다.
파인 튜닝 중 weight update 는 low intrinsic rank 를 가진다는 가정하에 2개의 low rank 행렬 AB 를 사용하여 업데이트한다.
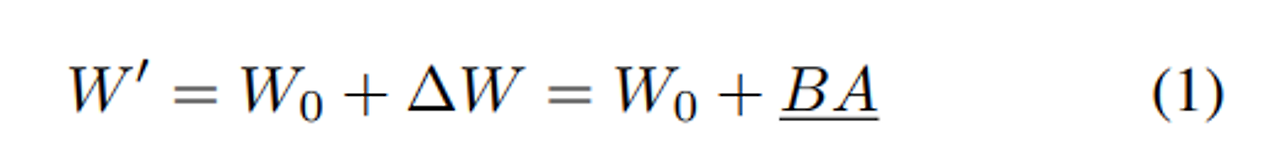
$W_0 ∈ R^{d×k}$ : pre-trained weight = 파인튜닝 동안 frozen
$∆W ∈ R^{d×k}$ : weight update
$B ∈ R^{d×r}$ (zero 초기화), $A ∈ R^{r×k}$ (uniform Kaiming distribution) → 처음 BA 는 0 이다.
fine-tuned weight 는 $W'$ 이다.
3.2. Weight Decomposition Analysis
LoRA 논문에서는 LoRA 의 rank r 을 큰 값을 사용할수록 FT 의 expressiveness를 approximate 할 수 있다고 주장한다.
따라서 이전 많은 연구들은 LoRA 와 FT 사이 정확도 차이가 trainable 파라미터 개수 차이에서 온다고 생각하였다.
-> 하지만 이 논문에서는 그 이유가 아님을 이 Weight Decomposition Analysis 를 통해 증명하고자 한다.
이 분석법은 Weight normalization 에서 영감을 받았다.
Analysis Method:

$W ∈ R^{d×k}$ : 를 분해하면 위의 2식과 같다.
$m ∈ R^{1×k}$ = magnitude vector
$V ∈ R^{d×k}$ = directional matrix
$|| · ||_c$ = 각 column 에 대한 행렬의 vector-wise norm (Norm2)
이 분해는 V /||V||c 행렬의 각 column 벡터가 unit 벡터가 되도록 하고 m 의 각각에 해당하는 scalar 가 각 벡터의 크기를 정의한다.
Analysis 는 다음과 같이 진행한다.
4 가지 이미지-텍스트 task에 대해 미세 조정된 VLBART 모델을 이용하여 weight decomposition analysis를 한다.
self-attn 모듈의 query/value weight만 LoRA 를 적용하는 것은 똑같다.
식 2 를 사용하여 pre-trained weight $W_0$ 와 full fine-tuned weight $W_{FT}$ , LoRA 와 merge된 $W_{LoRA}$ 를 분해한다.
W_0와 W_FT 사이의 크기와 방향성 변화는 아래와 같이 정의할 수 있다.

$∆M^t_{FT}$ : 크기 difference
$∆D^t_{FT}$ : 방향 difference → t training step 에서의 $W_0$ 와 $W_{FT}$ 사이.
cos : 코사인 유사도.
$M^{n,t}_{FT}$ 와 $M^n_0$ 은 각 크기 벡터의 n 번째 scalar 이고
이 때 $V^{n,t}_{FT}$ 과 $W^n_0$ 는 $V^t_{FT}$ 와 $W_0$ n번쨰 columns 이다.
W_LoRA와 W_0의 크기와 방향 차이도 식 (3)과 식 (4) 와 똑같이 계산된다.
분석을 위해 3개의 중간 training step 와 최종 체크포인트를 사용한다.
또한 각 layer 의 값을 비교한다.
Analysis Results:
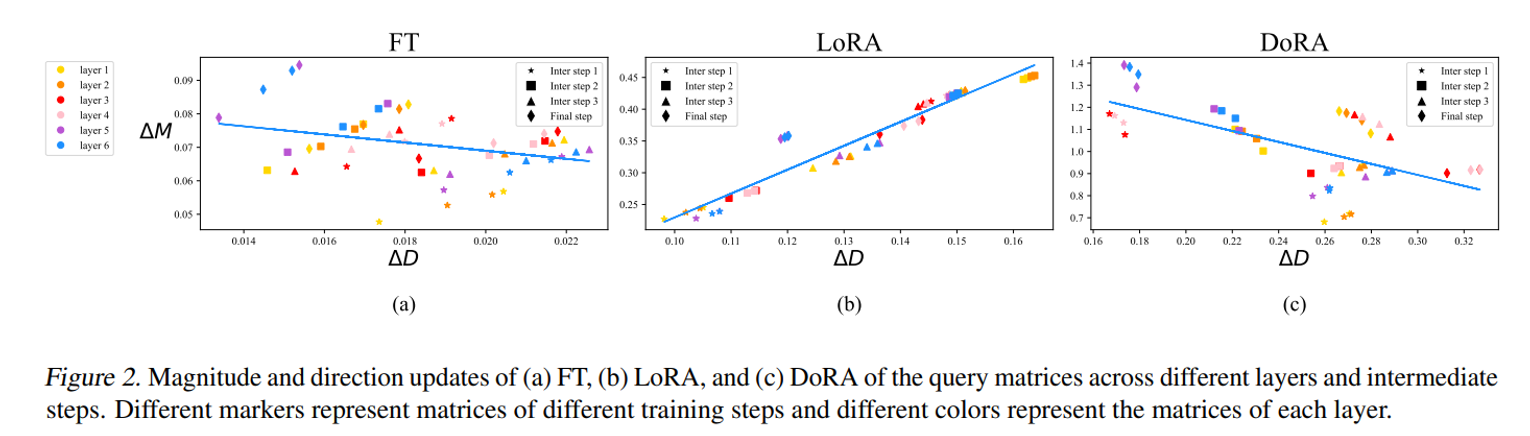
아직 DoRA 는 제안하지 않았으니 그림 2 의 a 와 b 만 살펴보자.
각각 FT 와 LoRA 의 쿼리 weight 행렬의 학습 step 에 따른 변화량을 보여준다.
각 점은 n 번째 layer 와 training step 에 따른 (attention 의) query weight 의 $(∆D_t, ∆M_t)$ 쌍을 나타낸다.

비슷하게 그림 5 는 value weight 행렬의 modification 이 표시되어있다.
LoRA 는 모든 중간 training step 에서 일관된 positive gradient 추세를 확인할 수 있고, 이는 방향과 크기 변화가 비례관계임을 나타낸다. 즉, magnitude 의 gradient 가 증가하면 direction 의 gradient 도 증가하고, 감소하면 반대도 감소한다는 것이다.
이와 대조적으로 FT 는 상대적으로 음의 기울기가 나타나는 것을 알 수 있다.
이 논문에서는 위 사실이 FT 가 더 다양한 학습 패턴을 보이는 것을 확인할 수 있는 것이라고 말한다.
LoRA 는 크기와 방향이 비례적으로 증가하거나 감소하는 성향이 더 섬세한 tuning 능력이 부족하다는 뜻이라는 것이다.
반대로 FT 의 negative 한 특성은 더 큰 magnitude의 변화과 함께 작은 direction 변화 나 그 반대를 실행할 수 있다는 뜻이다.
** 이해가 되는가? 필자는 약간 아리송한데, 만약 이 논문에서 FT 의 learning 패턴에 상관없이(FT 는 positive 가 나올수도있고, negative 가 나올수 있는) LoRA 의 analysis 그래프가 항상 positive 만 나온다는 사실을 같이 제공한다면 이해가 될지도 모르겠다.
이러한 LoRA 의 한계는 크기와 방향을 동시에 학습해야하는 문제가 LoRA 에게 복잡함을 나타낸다.
따라서 이 논문에서는 FT 와 더 유사한 학습 패턴을 보이도록, LoRA 보다 학습 capacity 를 늘릴 수 있는 LoRA 변형을 제안한다. 그것이 DoRA 이다.
4. Method

4.1. Weight Decomposition Low-rank Adaptation
weight 를 magnitude(크기)와 direction(방향)으로 나눈 후 둘 다 파인튜닝한다. 이 때, 방향 행렬의 파인튜닝에는 LoRA 를 사용한다.
Intuition
1. LoRA 가 directional adaptation 에만 집중하도록 제한하면서 magnitude 도 tunable 하도록 허용하면 크기와 방향 모두를 학습해야 하는 기존의 접근방식(LoRA) 에 비해 작업이 단순화된다.
2. 방향 업데이트를 최적화하는 과정은 가중치 분해를 통해 더 안정적으로 할 수 있다. (Sec 4.2)
이 논문은 Weight Normalization 에 영향을 받았는데, 주요 차이점은 훈련 방식이다.
Weight Normalization 은 크기와 방향 2개의 구성요소를 처음부터 훈련하기 때문에 다양한 initialization 방법들에 민감하게 반응할 수 있다.
하지만 DoRA 는 2개 구성요소를 모두 pre-trained weight W_0 에서부터 구하기 때문에 (pre-trained weight 로 초기화되었다고 할 수 있다) 이 문제를 피할 수 있다.
💡Weight Normalization 이란?
layer 의 가중치를 weight 의 eucleadian norm로 나눠서 weight 의 unit 벡터를 만드는 reparameterization 방법이다. $$w= \cfrac{g}{||v||}v$$
그래서 ||w||=g 가 되도록 한다. (이때 g는 scalar parameter이다.)
초기화 이후 magnitude $m = ||W_0||_c$ , directional matrix $V = W_0$ 이다.
그러고 나서 V 는 frozen 시키고 m 은 trainable 벡터로 유지한다.
방향 component 가 LoRA 를 통해 업데이트된다.
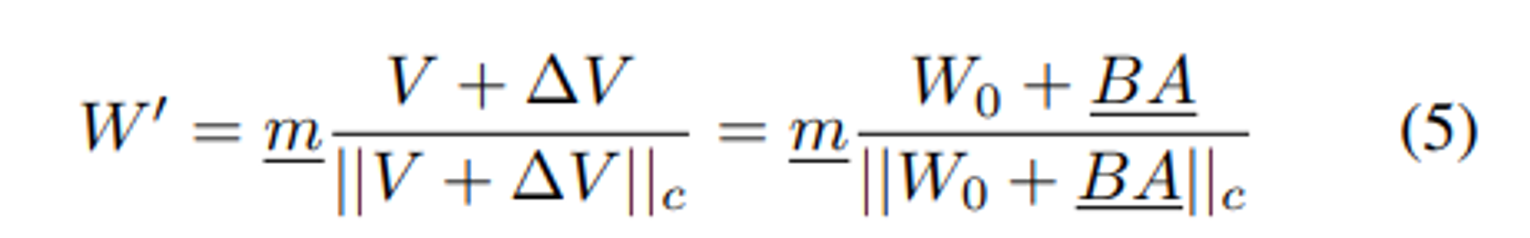
DoRA 도 LoRA 의 식 1 처럼 아래 5식과 같이 표현할 수 있다.
∆V : 는 2개 low-rank 행렬 B 와 A 를 곱해서 학습한 incremental directional update 이고,
밑줄친 parameter 가 학습가능한 파라미터이다.
$B ∈ R^{d×r}$ 와 $A ∈ R^{r×k}$ 는 fine-tuning 전에 W’ 가 W0 와 같을 수 있도록 LoRA 모듈과 똑같이 초기화된다.
DoRA 는 inference 전에 pre-trained weight 와 merge 할 수 있으므로 추가적인 latency 가 발생하지 않는다.
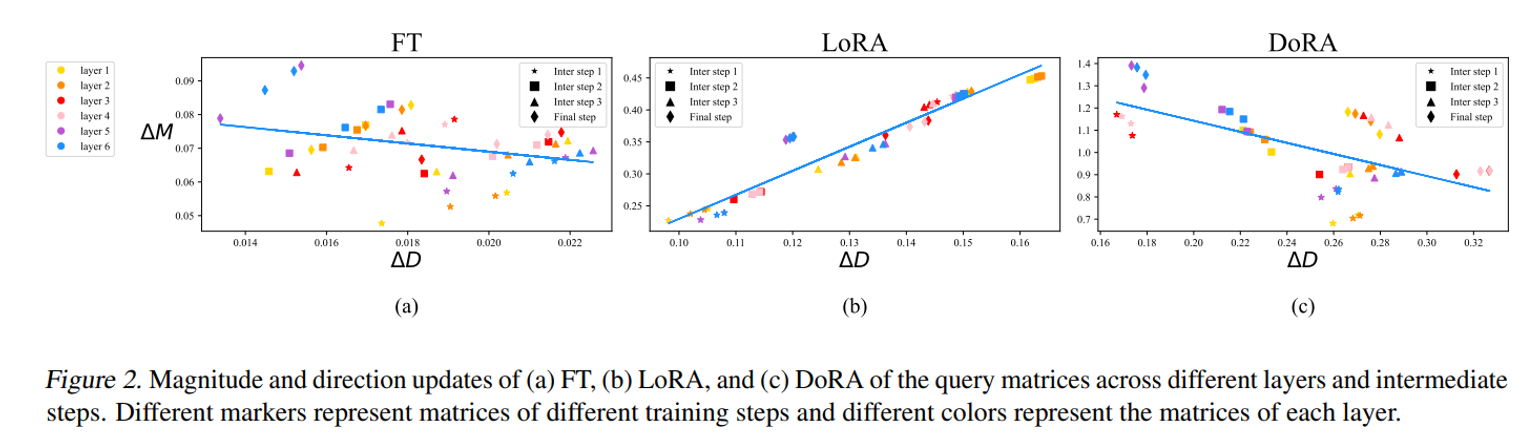
그림2 의 c. DoRA magnitudw 와 direction 변화량을 시각화한 그래프를 다시 보면,
(∆D, ∆M) 의 regression line 은 LoRA 와 달리 FT 처럼 DoRA 는 확실한 negative 기울기임을 확인할 수 있다.
FT 와 LoRA, DoRA 에 대한 (∆D, ∆M) 의 correlation를 확인할 결과 FT 와 DoRA 둘다 각각 -0.62와 -0.31의 음의 상관관계를 보이는 것을 확인했다.
반면, LoRA 는 0.83 로 양의 correlation을 확인하였다.
이 논문에서는 FT 의 변화량 기울기가 negative 인 이유는 pre-trained weights가 이미 다양한 downstream task 에 적합한 지식을 가지고있기 때문이라고 말한다. (=? 이미 pre train 에서 fine-tuning 에 필요한 지식이 있었다는 의미인강..)
그래서 적절한 학습용량만 있다면 더 큰 크기나 방향 변경만으로도 충분히 downsteam task adaptation 을 이룰 수 있다.
결과적으로 DoRA 가 FT 에 가까운 학습 패턴을 보이면서도 상대적으로 최소한의 크기 변화 + 상당한 방향 변화나 그 반대의 조정을 할 수 있다는 것은 LoRA 보다 더 좋은 학습능력을 가짐을 의미한다.
4.2. Gradient Analysis of DoRA
DoRA 그래디언트를 증명하고 ∆V 최적화에서 decomposition 이 어떤 장점이 있는지 설명한다.
그 후 negative 기울기를 가지는 DoRA 의 학습 패턴을 설명한다.
💡이 section 에서 알아야 할 수학 개념. 미분기호
$\Delta$ =단일변수의 변화량
$\nabla$ =편미분한 벡터 를 타나낸다.
$\nabla = \cfrac{d}{dx}i +\cfrac{d}{dy}j$ (i와 j 는 unit 벡터, 2차원일때)
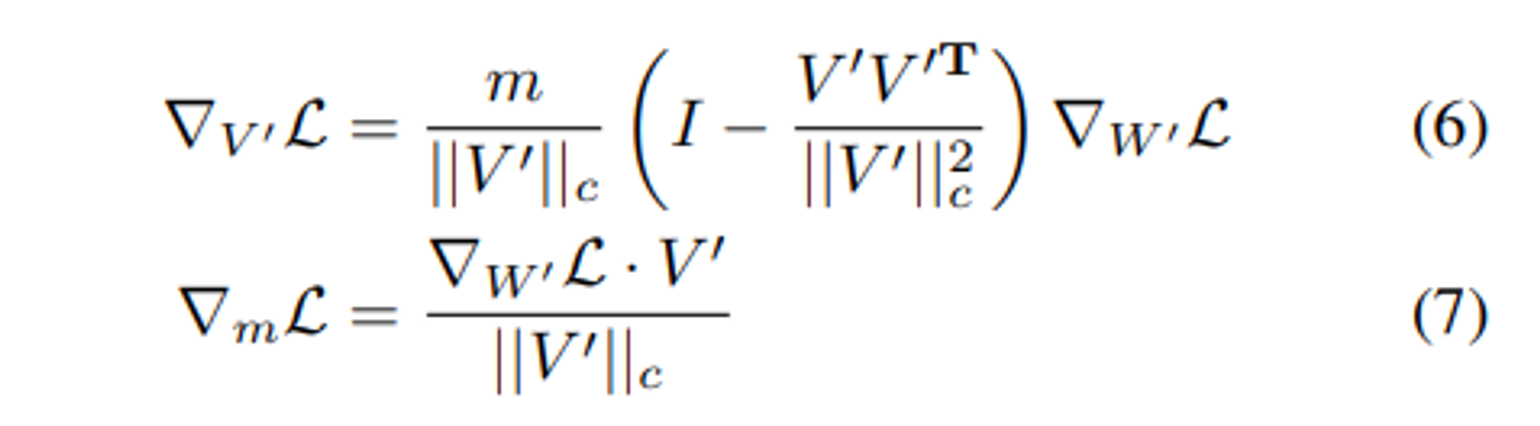
5식에서 처럼 Loss 함수의 gradient 를 m 와 V′ = V + ∆V에 따라 위 6,7 식과 같이 구할 수 있다.
$\nabla_{V'}L = \cfrac{dL}{dV'}$ 이다.
6 식은 weight gradient $\nabla_{W'}L$와 $\nabla_{V'}L$ 사이 관계를 나타낸다.
$∇_{W′}L$ 가 $\cfrac{m}{||V′||c}$에 의해 스케일링되고 현재 weight 행렬에 projection 된다.
이 2가지 효과는 gradient의 covariance(공분산) matrix 이 identity matrix 에 더 가깝게 align 되는데에 기여하고 이는 최적화에 유리하게된다. (Salimans & Kingma, 2016)
또한 V′ = V + ∆V 가 주어졌을 때 기울기 $∇_{V′}L$ 는 기울기 $∇_{∆V} L$ 와 같다. (V 는 pre-trained weight 의 direction 행렬인데 weight 는 frozen 되어있기 때문에 라고 추측한다.)
따라서 이 분해에서 파생된 최적화 이점은 ∆V로 완전히 전달되어 LoRA의 학습 안정성을 향상시킨다.
식 7 을 이용하여 학습 패턴의 insight 를 더 얻을 수 있다.
이후 discussion 을 확인하면 vector 를 이전의 행렬 notation 이 아니라 소문자로 표현한 것을 확인할 수 있다.
w′′ = w′ + ∆w : weight vecotr w 에 대한 파라미터 업데이트이다. (이 때 $∆w ∝ ∇_{w′}L$ )
2가지 가설적인 update 시나리오 S1 와 S2 에서
S1 은 더 작은 directional update (∆D_S1) 를 가지고 S2는 더 큰 update (∆D_S2) 를 가진다고 하자.
time = 0 에서 $||∆w_{S1}|| = ||∆w_{S2}||$ 라고 가정할 때 ∆v = 0 과 v′ = v 를 가진다.
$∆D_{S1} < ∆D_{S2}$ 에서 $|cos(∆w_{S1}, w′)| > |cos(∆w_{S2}, w′)|$ 를 얻을 수 있다.
$∆w ∝∇_{w′}L$, 이기 때문에 $|cos(∇^{S1}_{w′}L, w′)| > |cos(∇^{S2}_{w′}L, w′)|$ 이다.
섹션 4.1 에서 time=0 에서 v 는 v0 로 초기화되고 w’ =w0 가 되면
$|cos(∇_{w′}L, w′)| = |cos(∇_{w′}L, v′)| =|cos(∇_{w′}L, v)|$ 이다.
∆v = 0 일때 코사인 유사도 방정식 사용하면 아래 식과 같다.

이 때 m∗ 은 식 7에서 벡터 v’ 의 magnitude scalar 이고
그에 따라 m∗ 을 다시 쓰면 9식 과 같다.
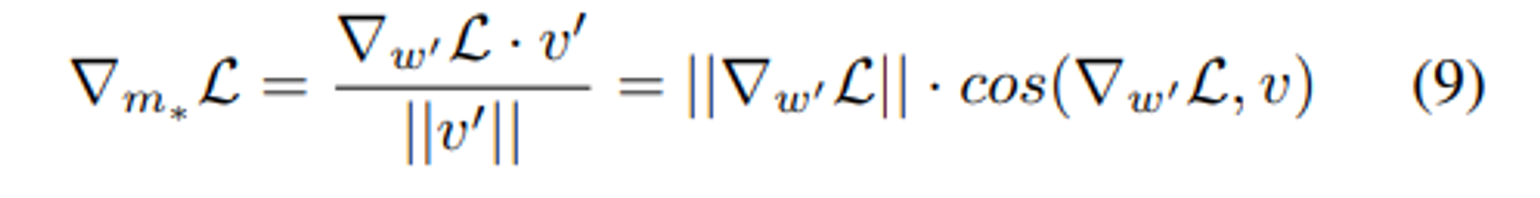
S1 과 S2 에 대해 $||∆w_{S1}|| = ||∆w_{S2}||$ 과 $||∇^{S1}_{w′}L|| = ||∇^{S2}_{w′}L||$ 가 같이 주어지면
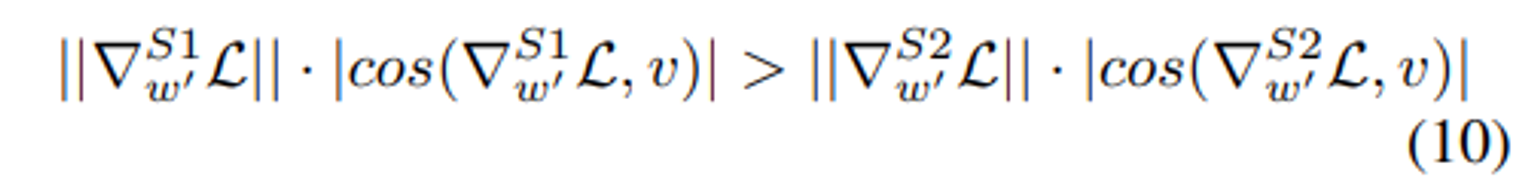
위는 $|∇^{S1}_{m∗}L| > |∇^{S2}_{m∗}L|$ 로 추론할 수 있다.
이는 S1이 S2보다 더 큰 크기 업데이트를 갖는 반면 방향성 변화는 S2보다 작다는 것을 나타낸다.
그림 2 (c)에서처럼 이러한 결론은 일반적으로 실제로도 적용된다.
결과적으로, 우리는 DoRA가 학습 패턴을 조정하는 데 어떻게 활용될 수 있는지 효과적으로 보여주었으며, LoRA의 패턴에서 벗어나 FT의 패턴에 더 가깝게 정렬할 수 있다.
4.3. Reduction of Training overhead
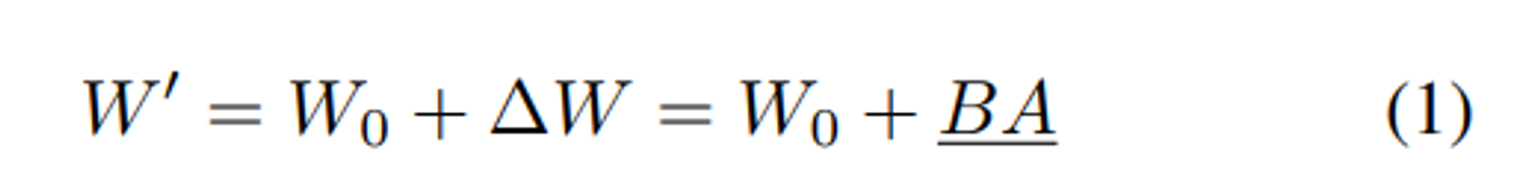
식 1에서 W’ 와 ∆W 의 gradient 는 똑같다.

하지만 방향 component 에 LoRA 를 적용하는 DoRA 를 사용하면, 식 6 처럼 low-rank 그래디언트는 W’ 와 다르다.
이러한 차이는 backpropagation 에서 추가적인 메모리를 필요로 한다.
위에서의 의미는$\cfrac{dL}{dV'} \neq \cfrac{dL}{dW'}$ 이다.

이 문제를 해결하기 위해 식 (5)의 ||V +∆V||c를 상수로 취급하여 backpropagation 의 계산 그래프에서 분리하는 것을 제안한다.
즉, ||V + ∆V||c는 ∆V의 업데이트를 동적으로 반영하지만 역전파 중에는 gradient 를 받지 않는다.
이렇게 수정하면 m 에 대한 gradient 는 변경되지 않고 $∇_{V′}L$은 다음과 같이 재정의된다:

이 접근방식은은 정확도가 별로 변하지 않고 gradient graph memory 사용을 줄인다.
LLaMA-7B 와 VLBART 파인튜닝에 미치는 영향을 평가하기 위해 ablation study 하였다.
그 결과 LLaMA 파인튜닝에서 약 24.4%의 훈련 메모리가 감소하고
VL-BART에서는 12.4%의 훈련 메모리가 감소했다.
게다가 이 modification이 적용된 DoRA 의 정확도는 VL-BART의 경우 변함이 없고, LLaMA에서 수정이 없는 DoRA와 비교했을 때 0.2 정도로 차이가 미미하다.
그래서 이후 모든 DoRA 는 이 조정이 적용된다.
5. Experiments
8가지 sub-tasks 의 commonsense reasoning 을 사용하여 성능을 비교하였다.
Prompt learning (Prefix), Series adapter (Series), Parallel adapter (Parallel) 의 PEFT 방식을 사용하여 fine-tuning 한 모델 LLaMA7B/13B 을 사용하였다.
또한 Chatgpt 는 gpt-3.5-turbo API 를 사용하여 프롬픝 엔지니어링을 통해 실험을 진행하였.
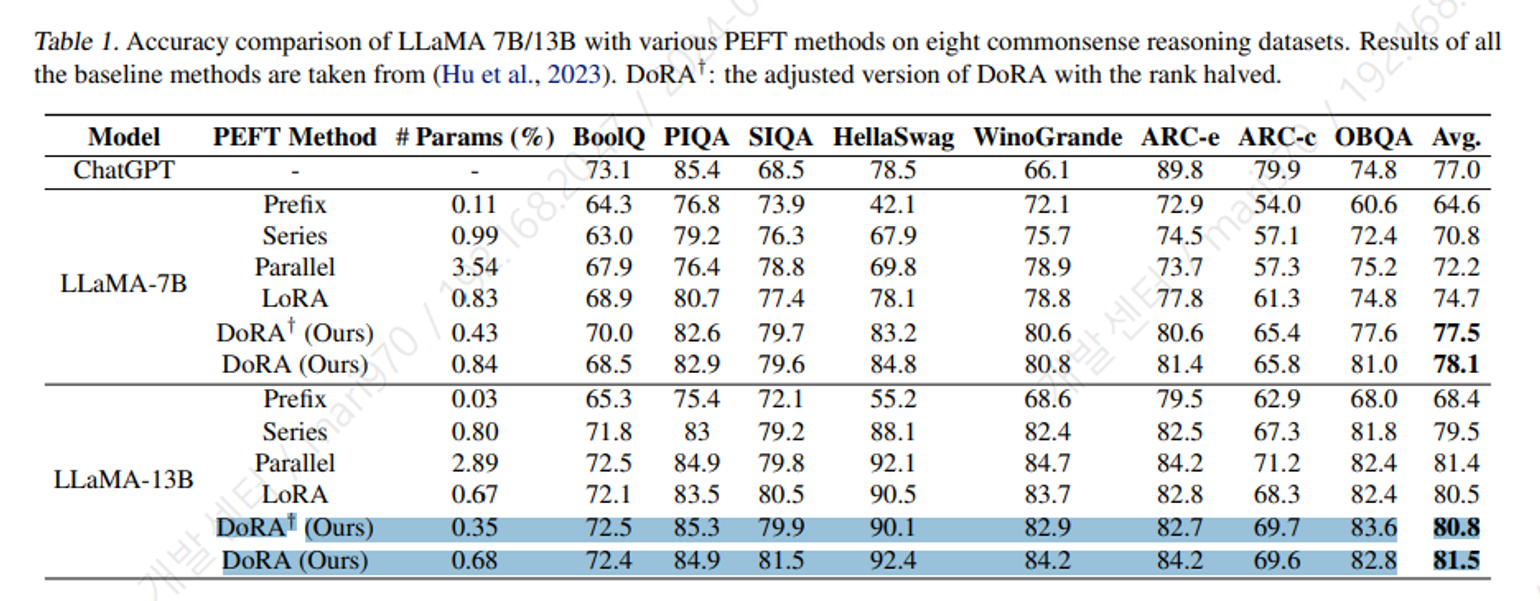
DoRA 가 LoRA 보다 trainable parameter 가 0.01% 많은 이유는 magnitude vector 를 추가적으로 학습해야하기 때문이다.
위 표와 같이 rank 사이즈를 반으로 사용한 DoRA 가 LoRA 보다 성능이 좋은것을 확인할 수 있었다.
또한 Image/Video-Text Understanding task 를 사용하여 실험을 진행하였다.
이 때, VL-BART 모델(vision encoder 과 encoderdecoder language model로 이루어진 모델) 을 사용하였다.

VQAv2 , GQA : visual question answering
MSCOCO : image captioning
TVQA , How2QA : video question answering
TVC , YC2C : video captioning 의 데이터셋을 사용한다.
위에서는 full fine-tuning 보다 DoRA 의 성능이 더 좋은 데이터셋이 있는 것을 확인할 수 있다.
Hugginface 사용방법
LoraConfig 에서 use_dora=True 를 사용하면 된다.
'LLM 관련 논문 정리' 카테고리의 다른 글
| Dataset Decomposition: Faster LLM Training with Variable Sequence Length Curriculum (0) | 2024.11.16 |
|---|---|
| RAGAS: Automated Evaluation of Retrieval Augmented Generation (1) | 2024.11.10 |
| LLAMA-2 from the ground up (0) | 2024.02.11 |
| SOLAR model paper (1) | 2024.01.13 |
| SPoT: Better Frozen Model Adaptation through Soft Prompt Transfer (0) | 2023.11.23 |