
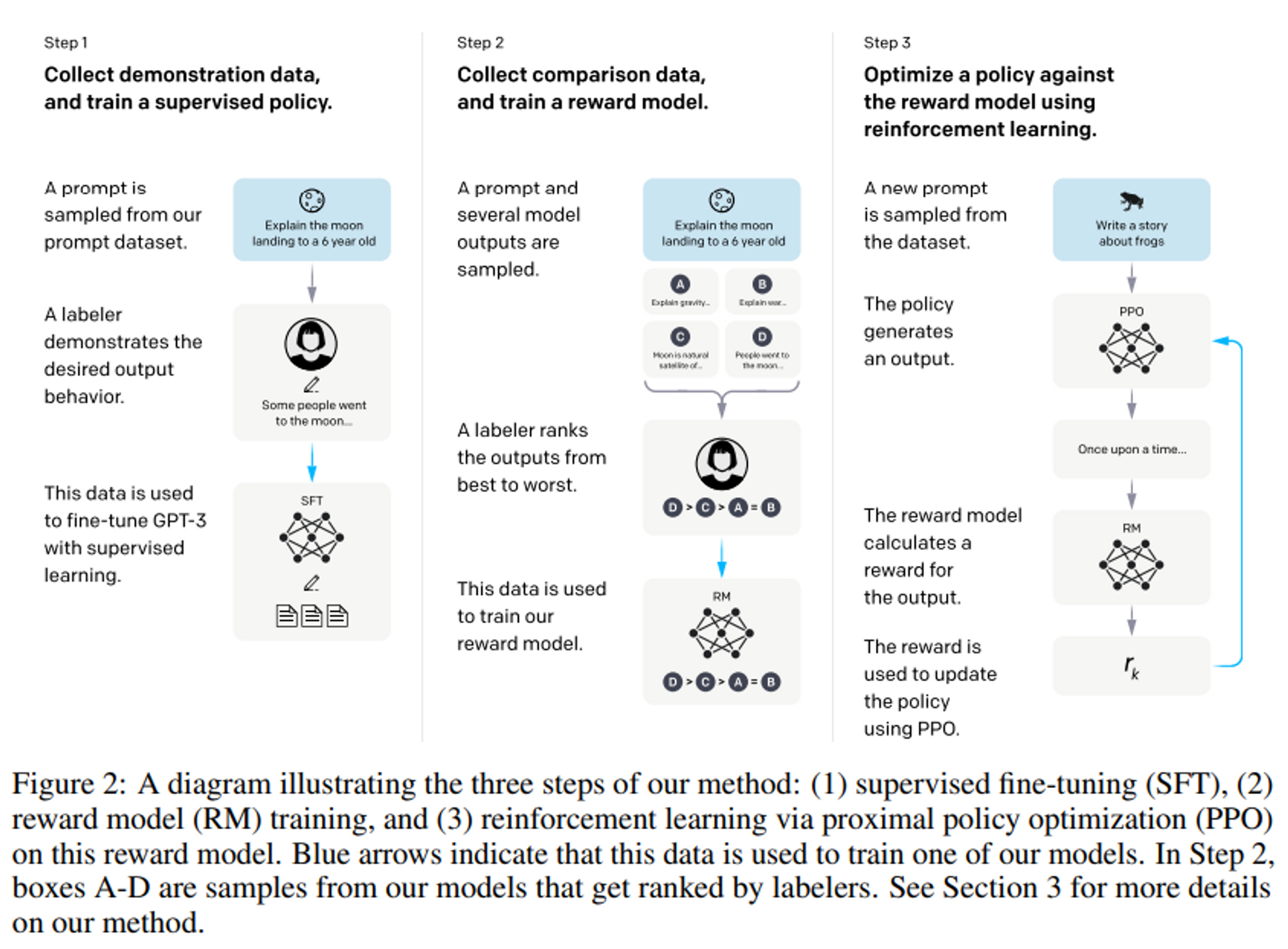
Language Model 을 크게 만든다고 해서 user 의 의도를 더 잘 따르는 것은 아니다.
LM의 안좋은 output 에는 1. untruthful 2. toxic 3. not helpful 이 있다.
이 논문에서는 human 피드백을 이용한 fine-tuning 을 통해 다양한 task 에 대한 user 의 의도를 맞추는 방법을 제시한다.
openAI 를 통해 수집한 프롬프트나 labeler(사람) 에 의해 작성된 프롬프트를 시작으로 원하는 모델 동작을 하는 labeler 시연 데이터셋을 모았다. 이를 통해 GPT-3 를 supervised learning 으로 fine-tuning 하는데 사용하였다.
이후 모델 output 에 대한 ranking 을 매겨 human feedback 강화학습을 사용하여 SFM 을 더욱 파인튜닝한다.
이 모델을 Instruct GPT 라고 부른다.
Model detail
모든 모델 아키텍처(SFT 와 RM 그리고 Value function)는 GPT-3 를 사용한다.
리워드 모델과 Value Function(PPO 에서 사용) 은 original 모델의 unembedding layer 를 scalar 가 나오도록 projection layer 로 대체하여 출력한다.
모든 모델은 BPE tokenizer 방법을 사용한다.
모든 언어모델과 policy 의 context 길이는 2k token 이다. 1k : 프롬프트 / 1k : response
모든 학습과정은 Adam optimizer 를 사용하였다. ($\beta_{1}$ = 0.9 $\beta_{2}$ = 0.95)
** PPO 에서도 Adam optimizer 를 사용한다.
** Comparison(SFT 모델의 1개 prompt 에 대한 여러 개의 response) 데이터를 모으고 RM 을 학습하는 step 2 와 PPO 를 사용하여 policy 를 학습하는 step 3 는 번갈아가며 반복된다.
새롭게 RM 을 학습시키고 그 PPO policy 를 가지고 다시 comparison 데이터를 모아 RM 을 학습시킨다.
Dataset detail
- SFT 모델을 학습하는 데에 사용하는 labeler 시연(& API) 데이터셋 : 13k 학습 프롬프트
- Reward 모델을 위한 labeler들이 모델의 output을 ranking 한 데이터셋 : 33k 학습 프롬프트 (labeler&API)
- RLHF(PPO) 파인튜닝의 인풋으로 사용되는 데이터셋 : 31k 학습 프롬프트 (API 만)
Step 1. SFT model 학습
데이터는 labeler 가 만든 demonstration (즉, 프롬프트와 사용자가 답변한 내용) 를 사용한다.
pre-trained GPT-3 를 supervision 으로 파인튜닝한다. 이를 SFT model 이라고 한다.
학습 디테일
Setting : 16 epochs, cosine lr decay, residual dropout 0.2
1 에폭 이후 validation loss 에 대해 overfitting 된다는 것을 확인할 수 있었다.
하지만 과적합에도 불구하고 더 많은 에폭을 사용했을 때 RM score 와 인간 선호도 점수 둘 다 도움이 되는 것을 확인하였기 때문에 16 에폭 사용.
Step 2. Reward Model 학습
파인튜닝된 모델 output으로 부터 비교군 데이터셋을 모으고, labeler 는 주어진 input 에 대해 더 선호하는 output 을 ranking 한다.
그리고 그 데이터셋으로 Reward model 을 학습시켜 human-preferred output 을 예측한다.
데이터 details
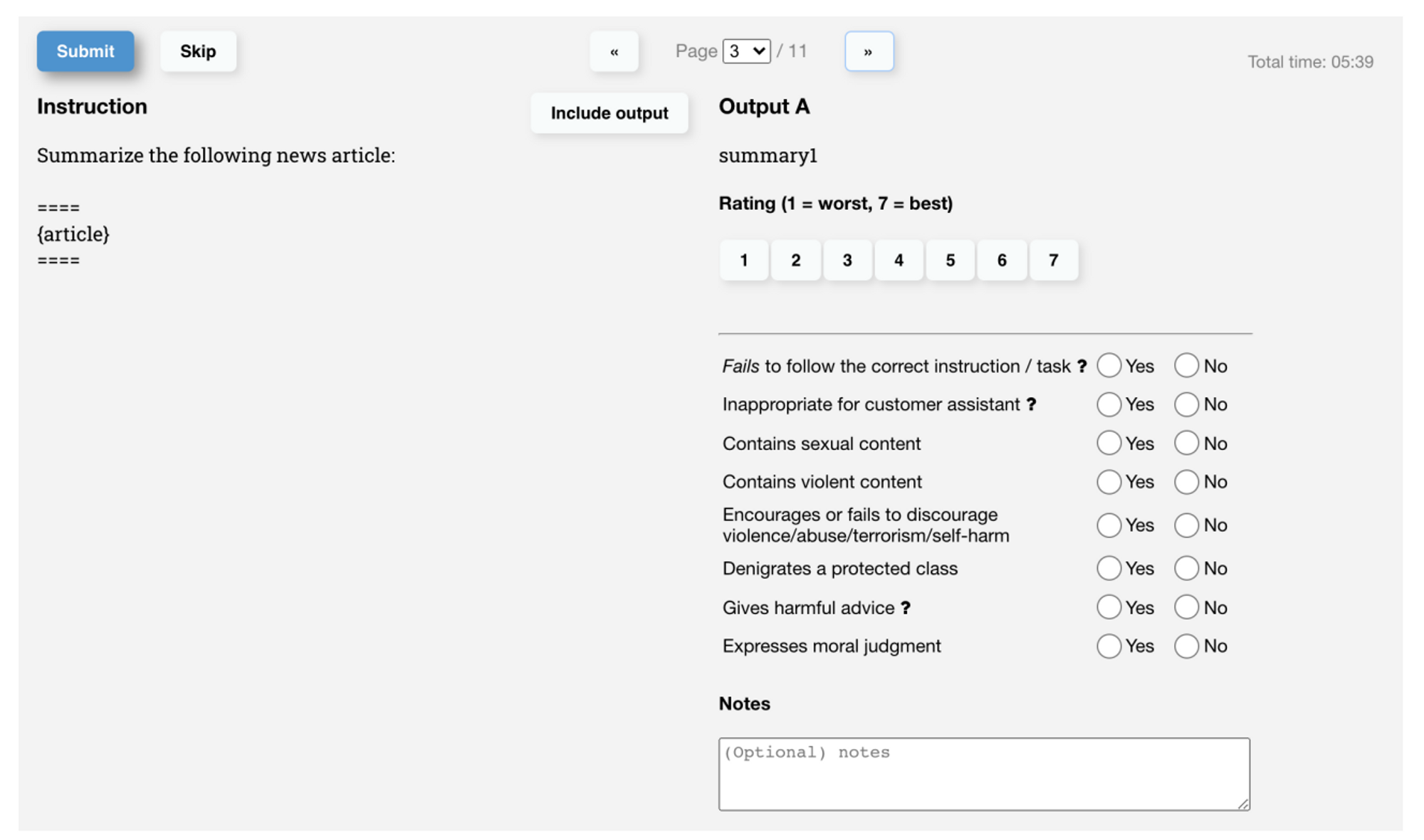
Labeler 가 매기는 score 는 1-7 까지 likert 척도로 Label 을 정한다.
이외 meta label 로서 harmful 한지, helpful 한지 등을 평가한다.
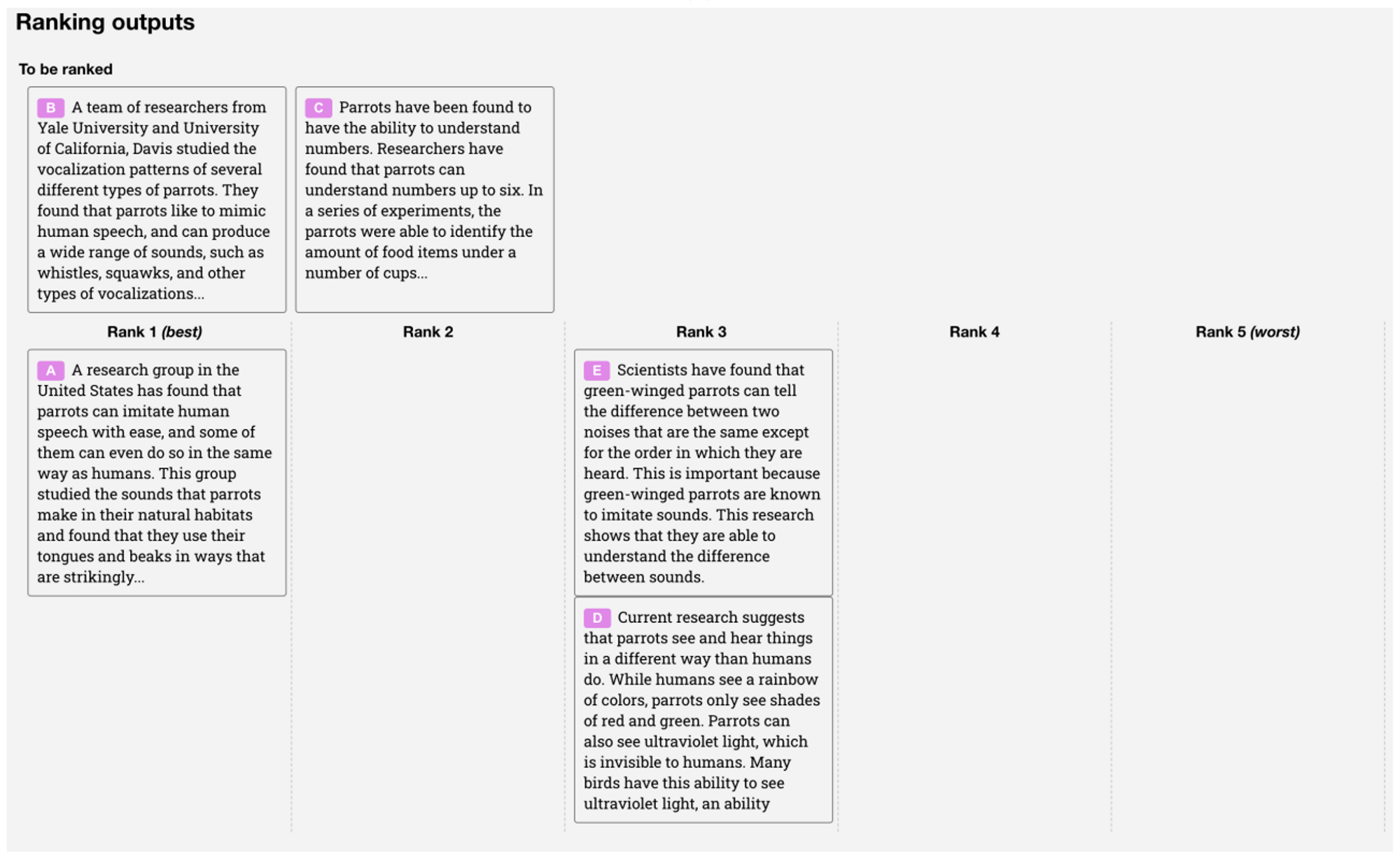
위의 Score 를 이용해 ranking 을 구한다. 더 나은지의 여부를 확실하게 하기 위해 척도를 도입.
Model details
RM은 다양한 public 데이터셋으로 파인튜닝된 6B gpt-3 를 사용했다.
Reward model 의 input : SFT 모델의 unembedding layer 이전 representation / output : scalar reward
학습 방법
comparison 수집을 빠르게 하기 위해 우리는 labeler 에게 K=4 에서 K=9 사이의 rank 를 가지는 response 를 제공한다.
이는 labeler에게 보여준 각 prompt에 대한 ${K \choose 2}$ 개의 rank 비교 를 생성한다.
계산적으로 효율적으로 하기 위해 각 prompt 에서 모든 ${K \choose 2}$ 개의 비교를 평균으로 나누어서 single batch 요소로 학습한다.
** 만약 각 가능한 ${K \choose 2}$ comparisons 가 (single batch 가 아니라) 각각의 data point로 취급된다면, 각 completion 잠재적으로 K − 1 개의 별도의 gradient update 에 사용된다. 모델은 single 에폭(아마 1 epoch) 이후 overfitting 되는 경향이 있기 때문에 1개 epoch 안에 data 가 반복되면 overfitting 을 일으킨다. ⇒ 그러므로 오버피팅 현상을 줄이는 효과도 있다.
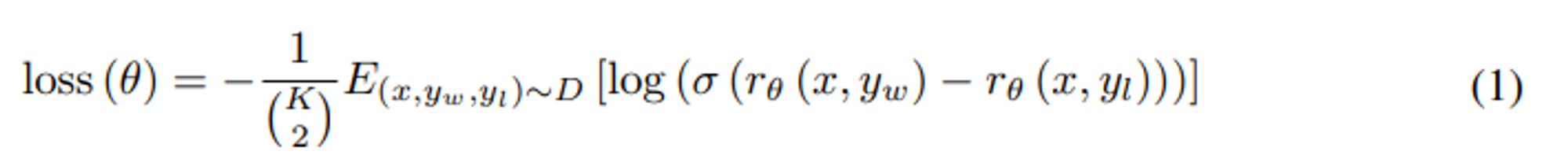
위는 RM 의 loss 함수.
$r_{θ}(x, y)$ : reward model 로 인풋은 prompt $x$ 와 completion $y$, scalar 아웃풋으로 나온다. 이때, $\theta$ 는 모델 파라미터
$y_{w}$ : $y_{w}$ 와 $y_{l}$ 쌍 중에 더 선호하는 completion(completion 이란 prompt+완성된 response)
$D$ : 사람 비교군 데이터셋
$\sigma$ : activation 함수 (초기의 multi-label 연구에서는 softmax 사용/ 그러므로 2개 에서는 sigmoid)
$log(\sigma(r_{\theta}(x, y_{w})-r_{\theta}(x, y_{l})))$ 차이는 labeler 가 y_w 를 y_l 보다 선호할 log 승산 $log(\frac{p}{(1-p)})$ 을 의미한다.
학습 디테일
Setting : lr = 9e-6 , batch size = 64 , cosine lr schedule , single epoch
training 은 lr 이나 scheduling 에 별로 민감하지 않았다. 하지만 epoch 에 민감했다. 여러 epoch 을 사용했을 때 빠르게 오버피팅했고 valid loss 가 악화되기 때문에 1 epoch 사용.
** 여기서 batch size 는 prompt 개수.
Step 3. PPO 학습
Reward 모델의 output을 scalar reward 로서 사용한다. 이 reward 를 최적화하기 위해 PPO 알고리즘을 이용하여 supervised policy 를 fine-tuning한다.
모든 PPO 모델에 대해 RM 과 Value 함수는 둘 다 6B gpt 를 사용하고 value 함수는 RM 로 초기화 된다.
Value 함수는 PPO 등의 RL 에서 사용하는 reward 에 대한 기댓값을 나타내는 함수라고 할 수 있다.
eval (추론) 시에는 사용하지 않는다.
PPO 학습 방법
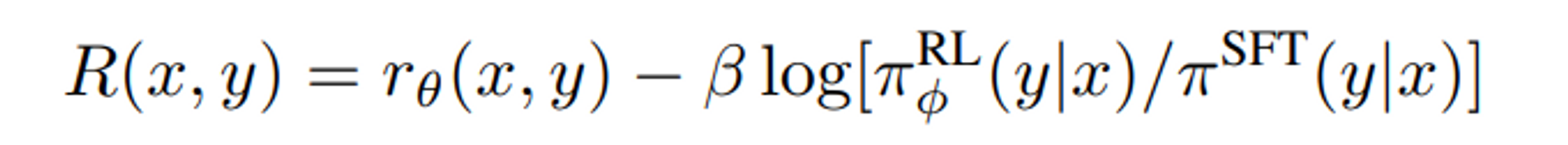
PPO 의 full reward 는 위의 식과 같다고 할 수 있다.
여기에 기댓값을 적용한 것이 밑의 objective 함수이다.
environment 는 랜덤으로 customer 프롬프트를 제공하고 그 프롬프트에 대한 response 를 얻도록 한다. 이렇게 생성된 prompt 와 response 가 주어졌을 때, reward 모델에 의해 결정된 reward 를 생성하고 그 후 episode (Agent 의 리워드 시퀀스) 를 중지한다.
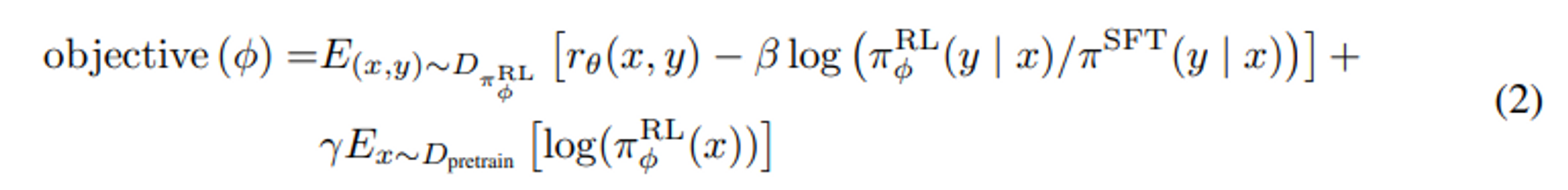
$\pi_{\phi}^{RL}$ : 학습된 RL policy
$\pi^{SFT}$ : supervised 학습된 모델
$D_{pretrain}$ : pretrain 된 distribution
$\beta$ : KL reward 계수
$\gamma$ : pre-training loss 계수 (PPO 모델에서는 0으로 세팅된다.)
위의 2개 계수는 각각 KL penalty 와 pre-training gradient 의 세기를 조절한다.
** PPO 에서는 Reward Model 이 학습되지는 않는다.
PPO loss 설명
$$ E_{(x, y) \sim D_{\pi^{RL}{\phi}}}[r{\theta}(x, y)] - \beta E_{(x, y) \sim D_{\pi^{RL}{\phi}}}[log(\frac{\pi^{RL}{\phi}(y|x)}{\pi^{SFT}(y|x)})] $$
또한 reward 모델의 over-optimization 을 완화하기 위해 SFT 모델에서 나온 각 토큰에서 token 별 KL penalty 를 추가한다.
즉, $\pi^{SFT}$ 는 weight 가 업데이트되지 않고 복사된 모델이 RL 을 이용해 따로 학습된다.
Pre-training gradient 추가
$$ \gamma E_{x \sim D_{pretrain}}[log(\pi^{RL}_{\phi}(x))] $$
또한 공개된 NLP 데이터셋에 대한 성능 regression 을 고치기 위해 pre-traing 그래디언트와 PPO 그래디언트 를 섞어 더 좋은 결과를 얻었다. 이를 “PPO-ptx” 라고 부른다.
이때, pre-train 에 사용된 데이터셋을 랜덤으로 샘플링하여 사용한다.
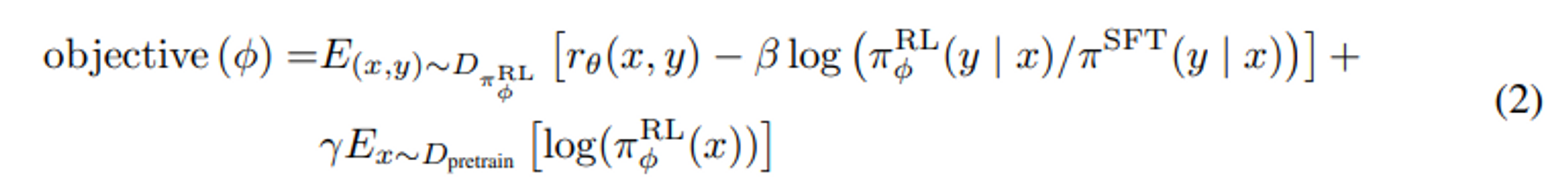
강화학습 에서 밑의 식 combined 된 objective 를 최대화한다.
** loss 식에 마이너스가 없기 때문에 자동으로 ascent 된다.
step 2 와 step 3는 반복해서 일어난다 : 새로운 Reward Model 을 학습하고 그 후 새로운 policy 를 학습하는데에 사용되는 더 많은 비교 데이터가 최근의 best policy 에서 수집된다.
Reference
Original InstructGPT paper
https://arxiv.org/pdf/2203.02155.pdf
Summarization with RLHF
https://arxiv.org/pdf/2009.01325.pdf
https://github.com/openai/summarize-from-feedback
Learning to summarize from human feedback
Reward model learning
https://arxiv.org/pdf/1909.08593.pdf
위에 논문 중요**
https://arxiv.org/pdf/1811.07871.pdf
https://arxiv.org/pdf/1909.01214.pdf
PPO
https://arxiv.org/pdf/1707.06347.pdf
https://pytorch.org/rl/tutorials/coding_ppo.html
Reinforcement Learning (PPO) with TorchRL Tutorial — torchrl main documentation
강화 학습 기초 - 정책(Policy), 가치 함수(Value Function) 그리고 벨만 방정식(Bellman Equation)
'LLM 관련 논문 정리' 카테고리의 다른 글
| Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning (NIPS, 2208) (0) | 2023.09.30 |
|---|---|
| PEFT (parameter-efficient fine tuning) 정리 (0) | 2023.09.18 |
| Rotary Position Embedding (RoPE) (0) | 2023.08.21 |
| NTK-aware dynamic interpolation (0) | 2023.08.21 |
| LoRA (Low-Rank Adaptation of Large Language Models) (0) | 2023.08.10 |