
Few-shot in-context learning (ICL) 은 pre-trained language models (PLM) 이 gradient-based training 없이 unseen task 를 몇 개의 예제만 주고 task 를 풀도록 하는 방법이다.
Parameter-efficient fine-tuning (PEFT) 는 작은 파라미터 셋을 학습시켜서 모델이 새로운 태스크에 adapt 하도록 하는 대안법이다.
이 논문에서는 (IA)^3 라고 불리는 새로운 PEFT 방법을 소개하고 T-Few 라고 하는 "T0 모델을 기반으로 작업별 튜닝이나 파라미터 업데이트 적게 새로운 task 를 할 수 있는 방법” 을 제안한다.
ICL 의 단점
- 워딩과 예시의 순서와 같은 프롬프트의 포맷이 달라지는 것이 모델 성능에 많은 영향을 미칠 수 있다.
- ICL 는 일반적으로 파인튜닝보다 성능이 떨어진다.
- 워딩과 예시의 순서와 같은 프롬프트의 포맷이 달라지는 것이 모델 성능에 많은 영향을 미칠 수 있다.
→ 이에 대한 PEFT 의 보완사항
- 최소한의 파라미터 업데이트를 이용하여 PLM 모델을 튜닝한다.
- 새로운 태스크에 대해 few-shot 으로 ICL 보다 성능이 좋아야 한다.
- in-batch Multi task 가 가능해야 한다.
Method
1. Backbone model
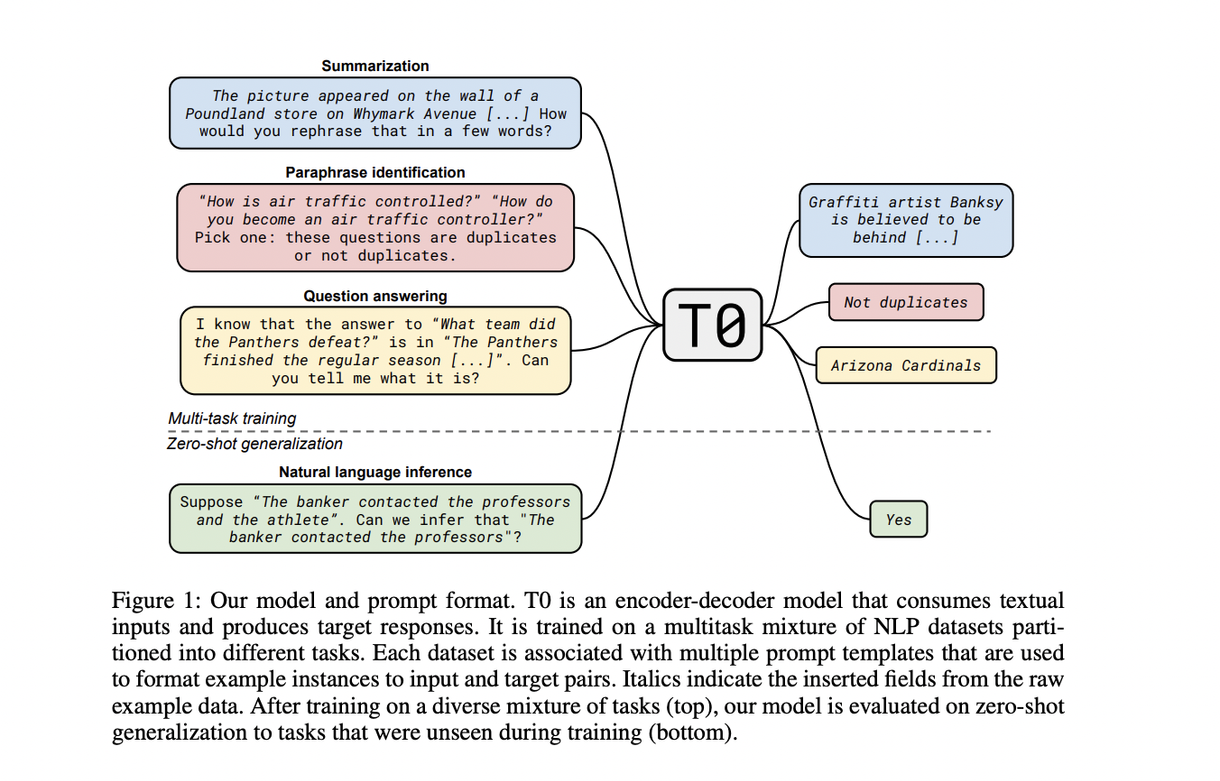
T0 사용 (T0 는 원래 zero-shot 일반화를 위해 설계된 모델이지만 이 논문에서는 아주 적은 labeled 데이터로 파인튜닝한 후에도 좋은 성능을 얻을 수 있음을 보여주려 한다)
T0 는 T5 모델을 베이스로 하는 encoder-decoder Transformer model 로, 큰 unlabeled text data에서 masked language modeling objective 로 학습된다.
T5 모델을 multitask 데이터셋으로 파인튜닝 한 것이다.
각각 T0-3B 와 그냥 T0 (11B) 가 있는데, 이 논문에서는 3B 를 사용.

2. 사용 Dataset
SuperGLUE 데이터셋 인 sentence completion (COPA [37], H-SWAG [38], Story Cloze [39] datasets), natural language inference (ANLI [40], CB [41], and RTE [42]), coreference resolution (WSC [43] and Winogrande [44]), 과 word sense disambiguation (WiC [45]) 를 사용해서 일반화 성능을 평가한다.
각 데이터셋을 퓨 샷 training 예제를 사용한다 : 20~70 개
데이터셋은 Public Pool of Prompts (P3) 의 프롬프트 탬플릿을 적용하여 학습에 사용하였다.
P3 는 각 데이터셋을 text-to-text format 으로 만들 수 있다.
💡 예를 들면, NLI task 에서 Premise, Hypothesis, Label 로 data example 이 이루어져 있을 때 :
**Input template : If {Premise} is true, is it also true that {Hypothesis}? target template : Choices[label]. # yes, maybe, no
https://huggingface.co/datasets/bigscience/P3
이후 (real-world few-shot learning benchmark) RAFT 벤치 마크 사용하여 Test 한다.
ICL 처럼 mixed-task batches 를 할 수 있어야 한다는 조건이 필요하다.
mixed batch 란 한 배치안에 각 샘플이 입력에 다른 context 와 프롬프트 를 concat하여 배치안의 예제마다 다른 task 를 수행하는 것을 말한다.
eval 에서는 “rank classification” 을 사용한다.
rank classification 은 모델의 모든 가능한 라벨에 대한 log-probabilities 를 ranking 해서 가장 높은 랭킹의 선택이 맞은 답일 때 모델의 예측이 맞았다고 간주한다.
→ 이는 multiple choice tasks 에서도 사용할 수 있다.
3. Loss function
일반적인 LM loss 함수
$y = (y1, y2, . . . , yT )$ : 이게 target 문장 일 때 cross-entropy loss
$$ L_{LM} = −\frac{1}{T}\sum_{t} \ log \ p(y_t|x, y_{<t}) $$
Unlikelihood loss
“rank classification” 을 사용하여 unlikelihood loss 를 구현한다.
⇒ 즉, rank classification 을 사용해서 모델이 결정한 맞은 선택 과 틀린 선택의 확률을 둘 다 고려한다.
training 중에 이를 고려하기 위해 unlikelihood loss 를 추가한다.

→ 밑은 평균을 취하지 않은 일반 sequence unlikelihood loss
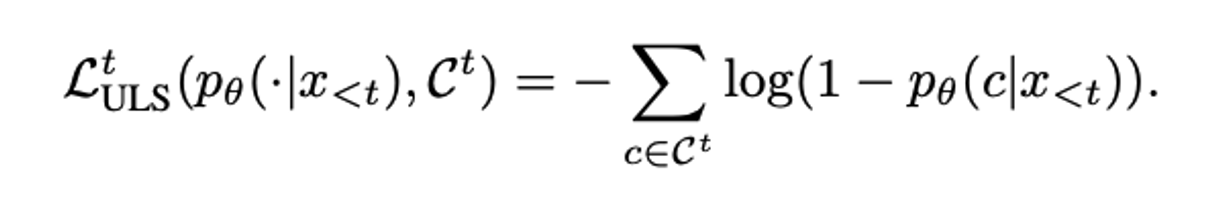
$\hat{y}{(n)} =(\hat{y_1}, \hat{y_2}, . . . , \hat{y}_{T^{(n)}} )$ : N 개(틀린 시퀀스 개수) 중 n 번째 틀린 target sequence,
$\hat{y}$ 는 예측한 토큰.
unlikelihood loss 는 틀린 토큰에 대해 계산하여 틀린 타겟 문장으로부터 다음 토큰을 예측하는 것을 막는 역할을 한다.
Length normalization loss
각 선택한 토큰에 확률에 따라 결과의 랭킹을 매기게 되면 더 짧은 선택을 선호할 수 있다. 왜냐하면 모델이 각 토큰에 배정한 확률은 1보다 작거나 같기 때문이다.

그래서 주어진 output 시퀀스의 length-normalized log probability 를 계산한다. : $β(x, y) = \frac{1}{T}\sum^{T}{t=1} \ log \ p(y_t|x, y{<t})$
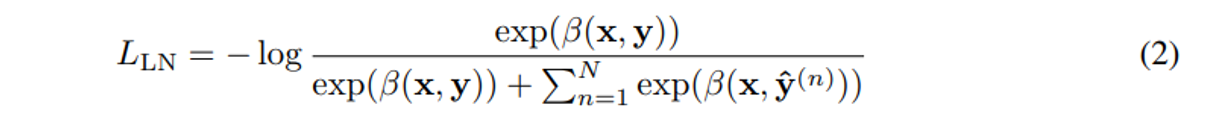
그 후, 2번 식 softmax cross-entropy loss 을 최소화 함으로서 맞은 answer 선택의 length-normalized log probability를 최대화한다. (→ 이럴거면 일반 cross entropy loss 를 굳이 추가한 이유는 모르겠음)
L_LM, L_UL, L_LN 으로 모델을 학습할 때 → 각 로스를 temperature(hyper-parameter) 없이 그냥 더했다.
그래서 모든 downstream 데이터셋에 대해 똑같은 방식으로 데이터셋에 따른 하이퍼파라미터 수정이 없이 사용할 수 있다.
4. Parameter-efficient fine-tuning with (IA)3
이 방법을 (IA)^3 라고 부른다. →“Infused Adapter by Inhibiting and Amplifying Inner Activations”
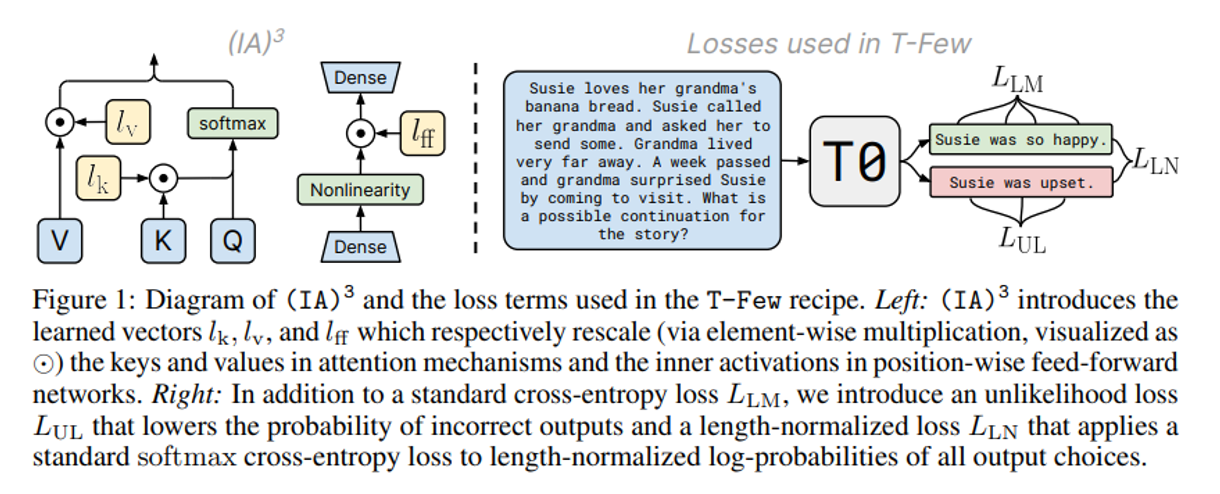
모델의 activation 에 element-wise multiplication 사용.
l 은 학습가능한 task specific vector 이고 ⊙는 element-wise multiplication 이다.
3가지 $l_k ∈ R^{d_k} , \ l_v ∈ R^{d_v} , \ l_{ff} ∈ R^{d_{ff}}$ 학습된 벡터를 어텐션의 키 와 밸류 와 FFN 에 도입한다.
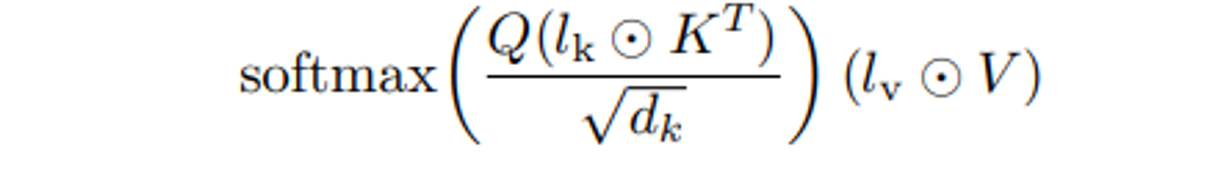
위는 어텐션에 적용한 식이고 밑은 position wise FFN 에 적용한 식이다.
$$ (l_{ff} ⊙ γ(W_1x))W_2 $$
$γ$ 는 FFN의 nonlinearity (activation 함수) 이다.
트랜스포머의 각 레이어 마다 적용하기 때문에 인코더에 L(d_k + d_v + d_{ff}) 개 파라미터, 디코더에 L(2d_k + 2d_v + d_{ff}) 개의 새로운 파라미터를 추가한다. → 디코더에는 셀프 어텐션과 그냥 어텐션이 2개 있기 때문.
6. 이외 학습 조건
1,000 steps , 8 batch size 에서 Adafactor optimizer 사용. learning rate = 3e−3 , linear decay schedule - 60-step warmup 사용.
Result
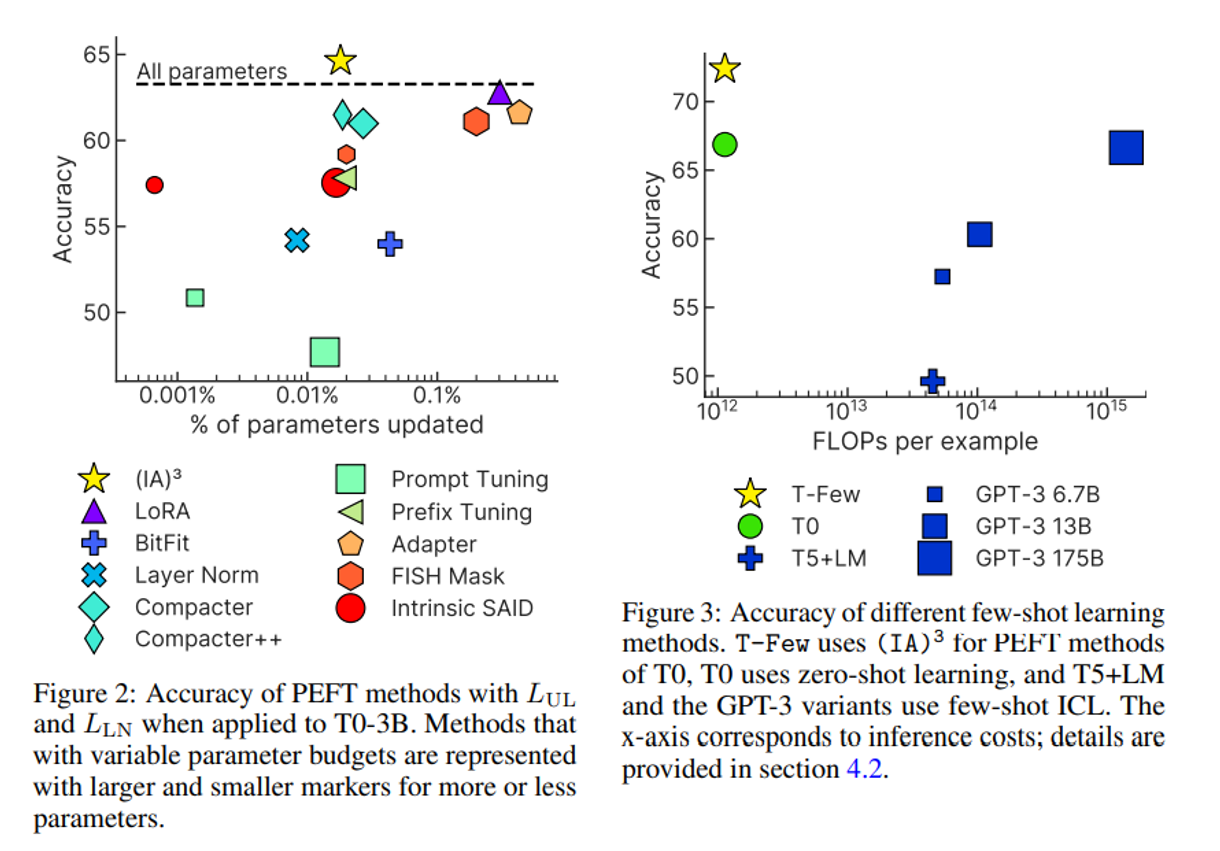
(IA)^3 을 평가하기 위해 T0 3B 모델에서 다양한 기존의 adaptation 방법과 비교한다.
특히 9가지의 PEFT 방법과 비교한다.
BitFit : bias 파라미터만 업데이트
Adapter : 셀프 어텐션이랑 position wise FFN 이후에 task specific layer 붙이는 것.
Compacter & Compacter++ : low rank 행렬과 hyper-complex(?) 곱을 이용해 어댑터를 발전시킴
Prompt tuning : task specific 프롬프트 임베딩을 모델 인풋에 콘캣해 학습시킴.
Prefix tuning : task specific 벡터를 모델 activation 에 콘캣하여 학습한다.
FISH Mask : 근사한 Fisher 정보를 바탕으로 파라미터 subset 을 업데이트
Intrinsic SAID : low-dimensional subspace 안에서 최적화를 진행.
LoRA : low rank 를 파라미터 행렬에 적용시킴.
그림 2 은 실험결과. Appendix D 에 각 데이터셋별 디테일 실험 결과가 있다.
(IA)3 가 모델 전체 파인튜닝 보다 더 높은 정확도를 얻는 유일한 방법임을 확인하였다.
** 성능이 좋은 PEFT 방법은 mixed-task batches 가 불가능하다!
성능 좋은 방법 중 LoRA 는 task 별로 기존 행렬에 더해주는 파라미터가 다르기 때문에 mixed-task 라고 할 수 없다.
-> 이런 느낌으로 불가능하다는 뜻인듯 하다. 본 논문에서 mixed task 를 해봤을때 진짜 성능이 떨어지는 지의 여부는 확인하지 않았다.
Performance on T0 tasks : 표1
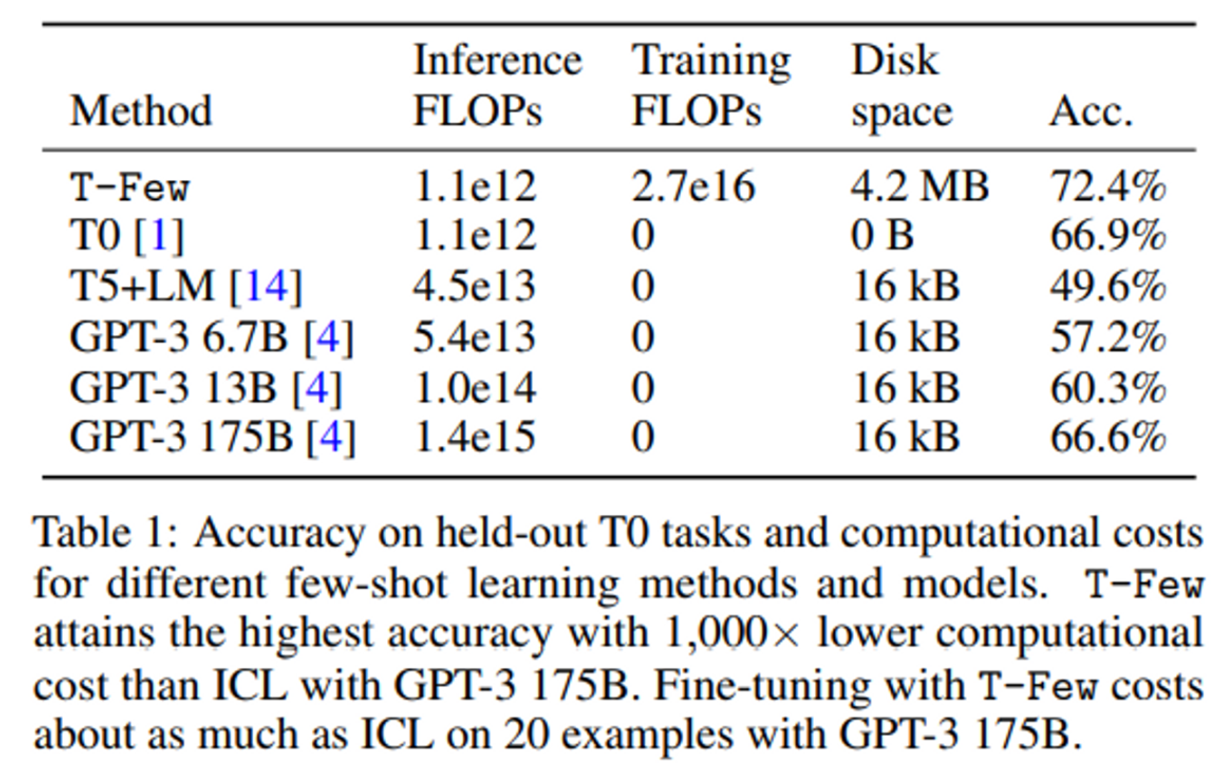
T-Few 가 다른 방법들보다 상당한 차이로 성능이 좋음을 확인.
특히 GPT-3 175B 의 few-shot ICL 보다 높은 정확도 얻음.
아래는 Appendix 표로, table 1 은 밑 표의 각 데티어테 대한 Accuracy 의 mean 값이다.
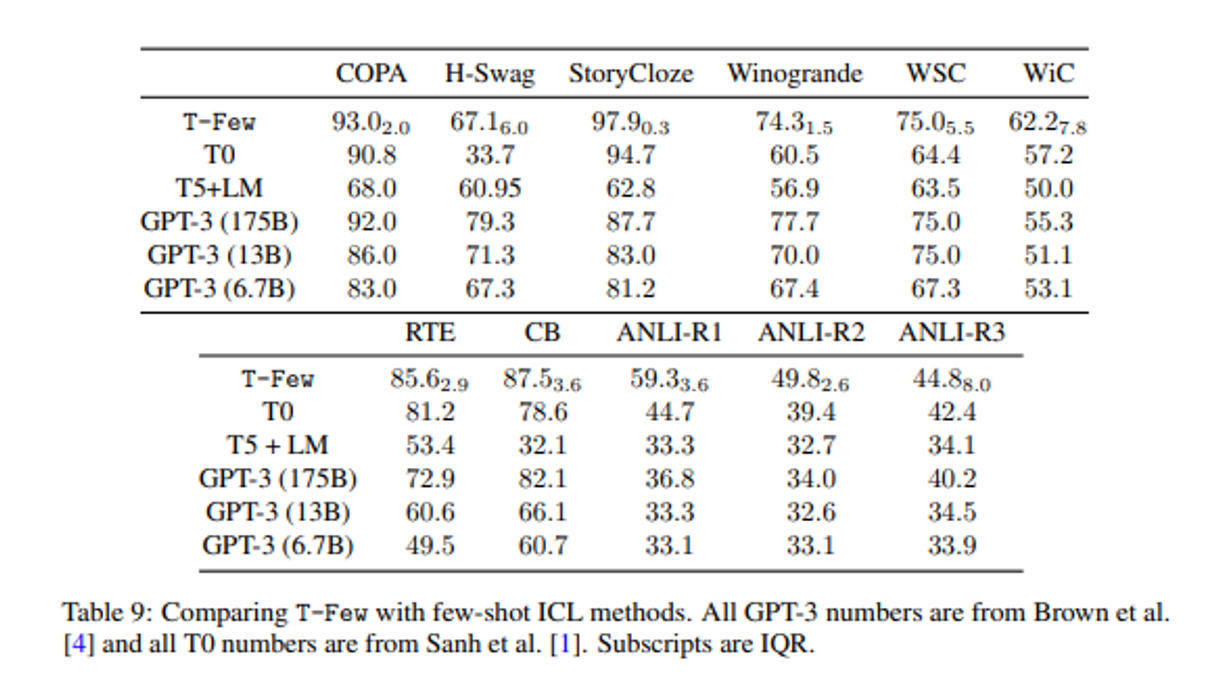
Comparing computational costs
💡 FLOPS = Floating point operations per second (speed 단위)
FLOPs = Floating point operations (개수 단위)
** decoder-only Transformer (즉 GPT series) 는 N parameters 일때 inference 에서 2N FLOPs per token 이고 학습에서 6N FLOPs per token 으로 추정된다.
** T0 , T5 과 같은 Encoder-decoder models 은 (where the encoder and decoder have the same number of layers and layer sizes) 각 토큰을 encoder 나 decoder 로만 처리하기 때문에 (거의 full 모델의 절반 정도 파라미터), FLOPs per token은 inference and training에서 각각 N 과 3N FLOPs per token 으로 추정된다.
cost 를 계산해보자.
inference 에서 모든 데이터셋에 대해 약 41개의 shot (중간값)을 사용한다고 가정.
input 과 targets 을 합친 것의 tokenized sequence length의 중간값은 103 이다.
few-shot ICL 에서 처리되는 in-context 예시들의 시퀀스 길이의 중간값은 98 이다.
key 와 value 벡터가 cached 되었다고 가정할 때, 1개 example 을 ICL 로 처리하려면 41 × 98 + 103 tokens 을 처리해야 한다.
Inference cost.
11e9×103 = 1.1e12 FLOPs : TFew 에서 1개 인풋에 대한 모든 타겟 choice 을 처리하는 데 필요한 양.
2×175e9×(41 × 98 + 103) = 1.4e15 FLOPs : GPT-3 175B 에서 few-shot ICL 할 때.
→ 3배가 더 걸린다. , 더 작은 GPT-3 에서도 더 많이 필요함.
Training cost.
T Few 만 training cost 가 든다.
3 × 11e9 × 1, 000 × 8 × 103 = 2.7e16 FLOPs. : ****11B 파라미터를 1000 step 으로 batch size 8 length 103 으로 학습
이는 GPT3 175B 으로 fewshot ICL 을 단일 예제로 처리하는데 필요한 FLOPs 보다 약 20배 크다.
즉 T Few 훈련은 ICL 로 20개의예제를 처리하는 것과 같은 비용이 든다.
Storage cost.
또한 제일 많은 storage cost 가 필요하다.
single-precision floats 으로 저장하면 IA3 에 의해 더해지는 파라미터수는 4.2MB 이다.
반면에 ICL 은 토큰화된 in context 예제만 저장하면 되므로 (보통 32bits integer로) : 41 × 98 × 32 bits = 16 kB 만큼 필요하다.
하지만 이는 모델 체크포인트 자체에 비하면 작다.T0 의 체크포인트 파일 크기는 41.5GB 이다.
Memory usage.
Inference 동안 주된 메모리 cost는 모델 파라미터 이다.
T0 보다 작은 모델은 GPT-3 6.7B 이다.반면에 T Few 는 inference 동안 더 적은 메모리양을 필요로 한다.
추가적인 메모리 코스트는 학습할 때 Adafactor 를 사용하고 백프롭을 하기위해 중간 activations 를 캐싱해서 생긴다.
→ TFew 로는 80GB A100 GPU 1개로 충분하다.
Real-world Few-shot Tasks (RAFT) : 표2

RAFT benchmark 은 11개의 “경제적으로 가치있는” 태스크에 대해 실제 응용이 가능한 데이터셋이다.
각 RAFT datasets 은 50개 학습 데이터 를 가지고 validation set 은 없고 더 큰 test set 은 public label 이 없다.
T-Few 는 75.8% 로 sota 를 찍었고, 참고로 휴먼은 73.5% 이다.
'LLM 관련 논문 정리' 카테고리의 다른 글
| NEFTune: Noisy Embeddings Improve Instruction Fine-tuning (0) | 2023.11.15 |
|---|---|
| CLM, MLM, TLM 그리고 Seq2Seq (0) | 2023.10.30 |
| PEFT (parameter-efficient fine tuning) 정리 (0) | 2023.09.18 |
| InstructGPT 상세 리뷰 (0) | 2023.08.30 |
| Rotary Position Embedding (RoPE) (0) | 2023.08.21 |
Few-shot in-context learning (ICL) 은 pre-trained language models (PLM) 이 gradient-based training 없이 unseen task 를 몇 개의 예제만 주고 task 를 풀도록 하는 방법이다.
Parameter-efficient fine-tuning (PEFT) 는 작은 파라미터 셋을 학습시켜서 모델이 새로운 태스크에 adapt 하도록 하는 대안법이다.
이 논문에서는 (IA)^3 라고 불리는 새로운 PEFT 방법을 소개하고 T-Few 라고 하는 "T0 모델을 기반으로 작업별 튜닝이나 파라미터 업데이트 적게 새로운 task 를 할 수 있는 방법” 을 제안한다.
ICL 의 단점
- 워딩과 예시의 순서와 같은 프롬프트의 포맷이 달라지는 것이 모델 성능에 많은 영향을 미칠 수 있다.
- ICL 는 일반적으로 파인튜닝보다 성능이 떨어진다.
- 워딩과 예시의 순서와 같은 프롬프트의 포맷이 달라지는 것이 모델 성능에 많은 영향을 미칠 수 있다.
→ 이에 대한 PEFT 의 보완사항
- 최소한의 파라미터 업데이트를 이용하여 PLM 모델을 튜닝한다.
- 새로운 태스크에 대해 few-shot 으로 ICL 보다 성능이 좋아야 한다.
- in-batch Multi task 가 가능해야 한다.
Method
1. Backbone model
T0 사용 (T0 는 원래 zero-shot 일반화를 위해 설계된 모델이지만 이 논문에서는 아주 적은 labeled 데이터로 파인튜닝한 후에도 좋은 성능을 얻을 수 있음을 보여주려 한다)
T0 는 T5 모델을 베이스로 하는 encoder-decoder Transformer model 로, 큰 unlabeled text data에서 masked language modeling objective 로 학습된다.
T5 모델을 multitask 데이터셋으로 파인튜닝 한 것이다.
각각 T0-3B 와 그냥 T0 (11B) 가 있는데, 이 논문에서는 3B 를 사용.
2. 사용 Dataset
SuperGLUE 데이터셋 인 sentence completion (COPA [37], H-SWAG [38], Story Cloze [39] datasets), natural language inference (ANLI [40], CB [41], and RTE [42]), coreference resolution (WSC [43] and Winogrande [44]), 과 word sense disambiguation (WiC [45]) 를 사용해서 일반화 성능을 평가한다.
각 데이터셋을 퓨 샷 training 예제를 사용한다 : 20~70 개
데이터셋은 Public Pool of Prompts (P3) 의 프롬프트 탬플릿을 적용하여 학습에 사용하였다.
P3 는 각 데이터셋을 text-to-text format 으로 만들 수 있다.
💡 예를 들면, NLI task 에서 Premise, Hypothesis, Label 로 data example 이 이루어져 있을 때 :
**Input template : If {Premise} is true, is it also true that {Hypothesis}? target template : Choices[label]. # yes, maybe, no
https://huggingface.co/datasets/bigscience/P3
이후 (real-world few-shot learning benchmark) RAFT 벤치 마크 사용하여 Test 한다.
ICL 처럼 mixed-task batches 를 할 수 있어야 한다는 조건이 필요하다.
mixed batch 란 한 배치안에 각 샘플이 입력에 다른 context 와 프롬프트 를 concat하여 배치안의 예제마다 다른 task 를 수행하는 것을 말한다.
eval 에서는 “rank classification” 을 사용한다.
rank classification 은 모델의 모든 가능한 라벨에 대한 log-probabilities 를 ranking 해서 가장 높은 랭킹의 선택이 맞은 답일 때 모델의 예측이 맞았다고 간주한다.
→ 이는 multiple choice tasks 에서도 사용할 수 있다.
3. Loss function
일반적인 LM loss 함수
: 이게 target 문장 일 때 cross-entropy loss
Unlikelihood loss
“rank classification” 을 사용하여 unlikelihood loss 를 구현한다.
⇒ 즉, rank classification 을 사용해서 모델이 결정한 맞은 선택 과 틀린 선택의 확률을 둘 다 고려한다.
training 중에 이를 고려하기 위해 unlikelihood loss 를 추가한다.
→ 밑은 평균을 취하지 않은 일반 sequence unlikelihood loss
: N 개(틀린 시퀀스 개수) 중 n 번째 틀린 target sequence,
는 예측한 토큰.
unlikelihood loss 는 틀린 토큰에 대해 계산하여 틀린 타겟 문장으로부터 다음 토큰을 예측하는 것을 막는 역할을 한다.
Length normalization loss
각 선택한 토큰에 확률에 따라 결과의 랭킹을 매기게 되면 더 짧은 선택을 선호할 수 있다. 왜냐하면 모델이 각 토큰에 배정한 확률은 1보다 작거나 같기 때문이다.
그래서 주어진 output 시퀀스의 length-normalized log probability 를 계산한다. :
그 후, 2번 식 softmax cross-entropy loss 을 최소화 함으로서 맞은 answer 선택의 length-normalized log probability를 최대화한다. (→ 이럴거면 일반 cross entropy loss 를 굳이 추가한 이유는 모르겠음)
L_LM, L_UL, L_LN 으로 모델을 학습할 때 → 각 로스를 temperature(hyper-parameter) 없이 그냥 더했다.
그래서 모든 downstream 데이터셋에 대해 똑같은 방식으로 데이터셋에 따른 하이퍼파라미터 수정이 없이 사용할 수 있다.
4. Parameter-efficient fine-tuning with (IA)3
이 방법을 (IA)^3 라고 부른다. →“Infused Adapter by Inhibiting and Amplifying Inner Activations”
모델의 activation 에 element-wise multiplication 사용.
l 은 학습가능한 task specific vector 이고 ⊙는 element-wise multiplication 이다.
3가지 학습된 벡터를 어텐션의 키 와 밸류 와 FFN 에 도입한다.
위는 어텐션에 적용한 식이고 밑은 position wise FFN 에 적용한 식이다.
는 FFN의 nonlinearity (activation 함수) 이다.
트랜스포머의 각 레이어 마다 적용하기 때문에 인코더에 L(d_k + d_v + d_{ff}) 개 파라미터, 디코더에 L(2d_k + 2d_v + d_{ff}) 개의 새로운 파라미터를 추가한다. → 디코더에는 셀프 어텐션과 그냥 어텐션이 2개 있기 때문.
6. 이외 학습 조건
1,000 steps , 8 batch size 에서 Adafactor optimizer 사용. learning rate = 3e−3 , linear decay schedule - 60-step warmup 사용.
Result
(IA)^3 을 평가하기 위해 T0 3B 모델에서 다양한 기존의 adaptation 방법과 비교한다.
특히 9가지의 PEFT 방법과 비교한다.
BitFit : bias 파라미터만 업데이트
Adapter : 셀프 어텐션이랑 position wise FFN 이후에 task specific layer 붙이는 것.
Compacter & Compacter++ : low rank 행렬과 hyper-complex(?) 곱을 이용해 어댑터를 발전시킴
Prompt tuning : task specific 프롬프트 임베딩을 모델 인풋에 콘캣해 학습시킴.
Prefix tuning : task specific 벡터를 모델 activation 에 콘캣하여 학습한다.
FISH Mask : 근사한 Fisher 정보를 바탕으로 파라미터 subset 을 업데이트
Intrinsic SAID : low-dimensional subspace 안에서 최적화를 진행.
LoRA : low rank 를 파라미터 행렬에 적용시킴.
그림 2 은 실험결과. Appendix D 에 각 데이터셋별 디테일 실험 결과가 있다.
(IA)3 가 모델 전체 파인튜닝 보다 더 높은 정확도를 얻는 유일한 방법임을 확인하였다.
** 성능이 좋은 PEFT 방법은 mixed-task batches 가 불가능하다!
성능 좋은 방법 중 LoRA 는 task 별로 기존 행렬에 더해주는 파라미터가 다르기 때문에 mixed-task 라고 할 수 없다.
-> 이런 느낌으로 불가능하다는 뜻인듯 하다. 본 논문에서 mixed task 를 해봤을때 진짜 성능이 떨어지는 지의 여부는 확인하지 않았다.
Performance on T0 tasks : 표1
T-Few 가 다른 방법들보다 상당한 차이로 성능이 좋음을 확인.
특히 GPT-3 175B 의 few-shot ICL 보다 높은 정확도 얻음.
아래는 Appendix 표로, table 1 은 밑 표의 각 데티어테 대한 Accuracy 의 mean 값이다.
Comparing computational costs
💡 FLOPS = Floating point operations per second (speed 단위)
FLOPs = Floating point operations (개수 단위)
** decoder-only Transformer (즉 GPT series) 는 N parameters 일때 inference 에서 2N FLOPs per token 이고 학습에서 6N FLOPs per token 으로 추정된다.
** T0 , T5 과 같은 Encoder-decoder models 은 (where the encoder and decoder have the same number of layers and layer sizes) 각 토큰을 encoder 나 decoder 로만 처리하기 때문에 (거의 full 모델의 절반 정도 파라미터), FLOPs per token은 inference and training에서 각각 N 과 3N FLOPs per token 으로 추정된다.
cost 를 계산해보자.
inference 에서 모든 데이터셋에 대해 약 41개의 shot (중간값)을 사용한다고 가정.
input 과 targets 을 합친 것의 tokenized sequence length의 중간값은 103 이다.
few-shot ICL 에서 처리되는 in-context 예시들의 시퀀스 길이의 중간값은 98 이다.
key 와 value 벡터가 cached 되었다고 가정할 때, 1개 example 을 ICL 로 처리하려면 41 × 98 + 103 tokens 을 처리해야 한다.
Inference cost.
11e9×103 = 1.1e12 FLOPs : TFew 에서 1개 인풋에 대한 모든 타겟 choice 을 처리하는 데 필요한 양.
2×175e9×(41 × 98 + 103) = 1.4e15 FLOPs : GPT-3 175B 에서 few-shot ICL 할 때.
→ 3배가 더 걸린다. , 더 작은 GPT-3 에서도 더 많이 필요함.
Training cost.
T Few 만 training cost 가 든다.
3 × 11e9 × 1, 000 × 8 × 103 = 2.7e16 FLOPs. : ****11B 파라미터를 1000 step 으로 batch size 8 length 103 으로 학습
이는 GPT3 175B 으로 fewshot ICL 을 단일 예제로 처리하는데 필요한 FLOPs 보다 약 20배 크다.
즉 T Few 훈련은 ICL 로 20개의예제를 처리하는 것과 같은 비용이 든다.
Storage cost.
또한 제일 많은 storage cost 가 필요하다.
single-precision floats 으로 저장하면 IA3 에 의해 더해지는 파라미터수는 4.2MB 이다.
반면에 ICL 은 토큰화된 in context 예제만 저장하면 되므로 (보통 32bits integer로) : 41 × 98 × 32 bits = 16 kB 만큼 필요하다.
하지만 이는 모델 체크포인트 자체에 비하면 작다.T0 의 체크포인트 파일 크기는 41.5GB 이다.
Memory usage.
Inference 동안 주된 메모리 cost는 모델 파라미터 이다.
T0 보다 작은 모델은 GPT-3 6.7B 이다.반면에 T Few 는 inference 동안 더 적은 메모리양을 필요로 한다.
추가적인 메모리 코스트는 학습할 때 Adafactor 를 사용하고 백프롭을 하기위해 중간 activations 를 캐싱해서 생긴다.
→ TFew 로는 80GB A100 GPU 1개로 충분하다.
Real-world Few-shot Tasks (RAFT) : 표2
RAFT benchmark 은 11개의 “경제적으로 가치있는” 태스크에 대해 실제 응용이 가능한 데이터셋이다.
각 RAFT datasets 은 50개 학습 데이터 를 가지고 validation set 은 없고 더 큰 test set 은 public label 이 없다.
T-Few 는 75.8% 로 sota 를 찍었고, 참고로 휴먼은 73.5% 이다.
'LLM 관련 논문 정리' 카테고리의 다른 글
| NEFTune: Noisy Embeddings Improve Instruction Fine-tuning (0) | 2023.11.15 |
|---|---|
| CLM, MLM, TLM 그리고 Seq2Seq (0) | 2023.10.30 |
| PEFT (parameter-efficient fine tuning) 정리 (0) | 2023.09.18 |
| InstructGPT 상세 리뷰 (0) | 2023.08.30 |
| Rotary Position Embedding (RoPE) (0) | 2023.08.21 |